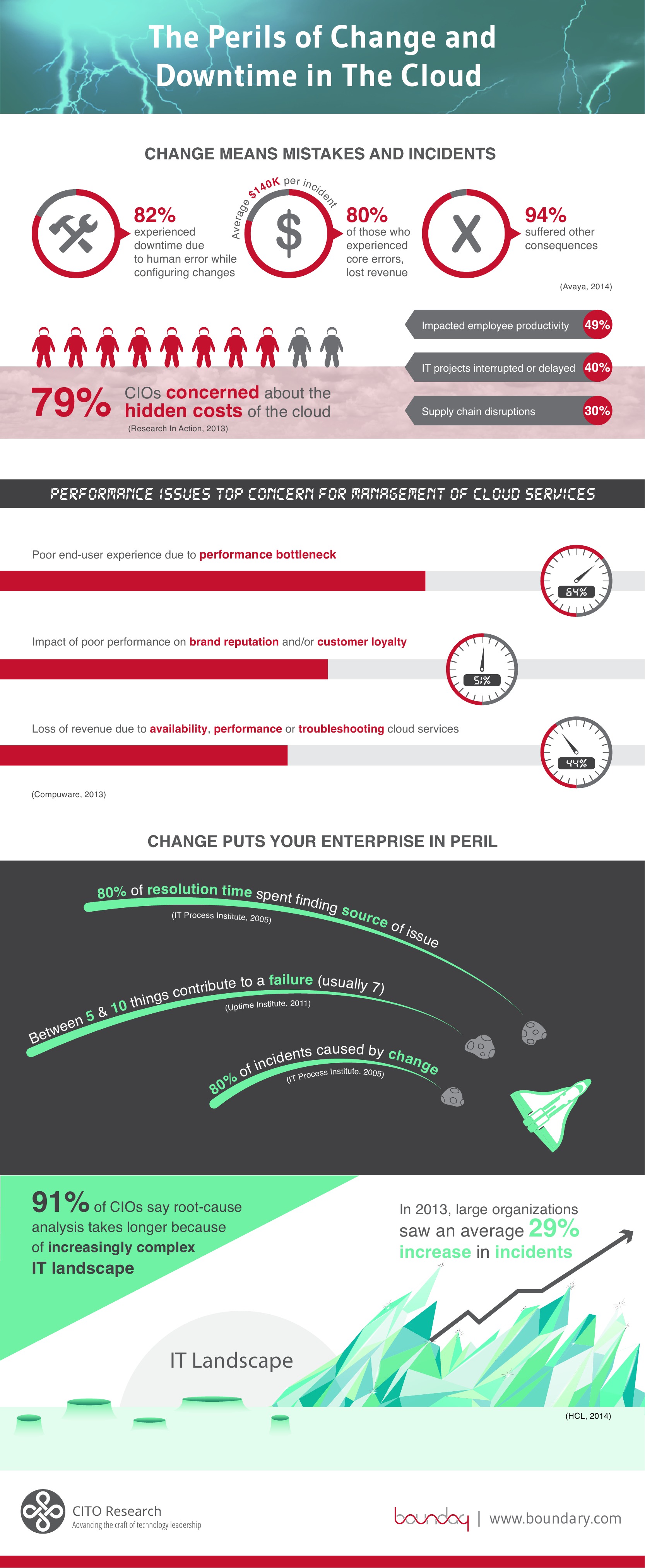
The mantra for developers at Facebook for the longest time has been "move fast and break things". The idea behind this philosophy being that the stigma around screwing up and breaking production slows down feature development, therefore if one removes the stigma from breakage, more agility will result. The cloud readily embodies this philosophy, since it is explicitly made of of unreliable components. The challenge for the enterprise embracing the cloud is to build up the processes and resiliency necessary to build reliable systems from unreliable components. Otherwise, moving to the cloud will mean that your customers are the first people to notice when you are experiencing downtime.
So what changes are necessary to remove the costs of downtime in the cloud? Foremost what is needed is a move to a more resilient architecture. The health of the service as a whole cannot rely on any single node. This means no special nodes: everything gets installed onto multiple instances with active-active load balancing between identical services. Not only that, but any service with a dependency must be able to survive that dependency going away. Writing code that is resilient to the myriad failures that may happen in the cloud is an art unto itself. No one will be good at it to start. This is where process and culture modifications come in.
It turns out that if you want programmers to write code that behaves well in production, an effective way to achieve that is to make them responsible for the behavior of their code in production. The individual programmers go on pager rotation and because they have to work side by side with the other people on rotation, they are held accountable for the code they write. It should never be an option to point to the failure of another service as the cause of your own service's failure. The writers of each discrete service should be encouraged to own their availability by measuring it separately from that of their dependencies. Techniques like serving stale data from cache, graceful degradation of ancillary features, and well reasoned timeout settings are all useful for being resilient while still depending on unreliable dependencies.
If your developers are on pager rotation, then there should be something to page them about. This is where monitoring comes in. Monitoring alerts come in two basic flavors: noise and signal. Monitoring setups with too many alerts configured will tend to be noisy, which leads to alert fatigue.
A good rule of thumb for any alerts you may have setup are that they be: actionable, impacting, and imminent. By actionable, I mean that there is a clear set of steps for resolving the issue. An actionable alert would be to tell you that a service has gone down. Less actionable would be to tell you that latencies are up, since it isn't clear what, if anything, you could do about that.
Impacting means that without human intervention the underlying condition will either cause or continue to cause customer impact.
And imminent means that the alert requires immediate intervention to alleviate service disruption. An example of a non-imminent alert would be alerting that your SSL certificates were due to expire in a month. Impactful and actionable, absolutely. But it doesn't warrant getting out of bed in the middle of the night.
At the end of the day, adopting the cloud alone isn't going to be the silver bullet that automatically injects agility into your team. The culture and structure of the team must be adapted to fit the tools and platforms they use in order to get the most out of them. Otherwise, you're going to be having a lot of downtime in the cloud.
Cliff Moon is CTO and Founder of Boundary.
The Latest
While most companies are now deploying cloud-based technologies, the 2024 Secure Cloud Networking Field Report from Aviatrix found that there is a silent struggle to maximize value from those investments. Many of the challenges organizations have faced over the past several years have evolved, but continue today ...
In our latest research, Cisco's The App Attention Index 2023: Beware the Application Generation, 62% of consumers report their expectations for digital experiences are far higher than they were two years ago, and 64% state they are less forgiving of poor digital services than they were just 12 months ago ...
In MEAN TIME TO INSIGHT Episode 5, Shamus McGillicuddy, VP of Research, Network Infrastructure and Operations, at EMA discusses the network source of truth ...

A vast majority (89%) of organizations have rapidly expanded their technology in the past few years and three quarters (76%) say it's brought with it increased "chaos" that they have to manage, according to Situation Report 2024: Managing Technology Chaos from Software AG ...
In 2024 the number one challenge facing IT teams is a lack of skilled workers, and many are turning to automation as an answer, according to IT Trends: 2024 Industry Report ...
Organizations are continuing to embrace multicloud environments and cloud-native architectures to enable rapid transformation and deliver secure innovation. However, despite the speed, scale, and agility enabled by these modern cloud ecosystems, organizations are struggling to manage the explosion of data they create, according to The state of observability 2024: Overcoming complexity through AI-driven analytics and automation strategies, a report from Dynatrace ...
Organizations recognize the value of observability, but only 10% of them are actually practicing full observability of their applications and infrastructure. This is among the key findings from the recently completed Logz.io 2024 Observability Pulse Survey and Report ...
Businesses must adopt a comprehensive Internet Performance Monitoring (IPM) strategy, says Enterprise Management Associates (EMA), a leading IT analyst research firm. This strategy is crucial to bridge the significant observability gap within today's complex IT infrastructures. The recommendation is particularly timely, given that 99% of enterprises are expanding their use of the Internet as a primary connectivity conduit while facing challenges due to the inefficiency of multiple, disjointed monitoring tools, according to Modern Enterprises Must Boost Observability with Internet Performance Monitoring, a new report from EMA and Catchpoint ...
Choosing the right approach is critical with cloud monitoring in hybrid environments. Otherwise, you may drive up costs with features you don’t need and risk diminishing the visibility of your on-premises IT ...
Consumers ranked the marketing strategies and missteps that most significantly impact brand trust, which 73% say is their biggest motivator to share first-party data, according to The Rules of the Marketing Game, a 2023 report from Pantheon ...



