Picture this: an application on your network is running slow. Before you even understand what the problem is, the network is blamed for the issue. This puts network teams in a dangerous position — guilty until proven innocent.
Even when network teams are sure an issue doesn't stem from a network problem, they are still forced to prove it, spending sometimes significant amounts of time going through troubleshooting processes, looking for a problem that doesn't exist. Because of this, the network team is often the last one stuck holding the ball, so to speak, due to their manual, one-device-at-a-time troubleshooting process, while other teams are able to complete their troubleshooting faster with more advanced tools.
Unfortunately, as long as companies depend on applications to conduct business, and applications depend on the network to function, the blame game between the two teams for slow performance, downtime or otherwise, will continue. However, there are ways network teams can ensure there's infrastructure in place to support given applications, and steps the network team can take to turn the tables to "innocent until proven guilty," when the applications aren't functioning properly.
First things first, when an application is down — no matter who's to blame — the issue still needs to be resolved. NetBrain's State of the Network Engineer Survey found that roughly 40 percent of network teams say it takes more than four hours to troubleshoot a "typical" issue. With applications being seen as a major driver of business value, those four hours can equate to hundreds of thousands of dollars lost. This is why network teams must find ways to reduce their mean time to repair (MTTR).
When it comes to MTTR, the "repair" part is typically a relatively quick and easy fix, but the mean time to identify (MTTI) the issue, or in this case MTTI(nnocence), is the more challenging part of the equation. In fact, about 80 percent of our MTTR time is spent trying to identify and locate the problem, while only 20 percent of our time is truly spent on repair.
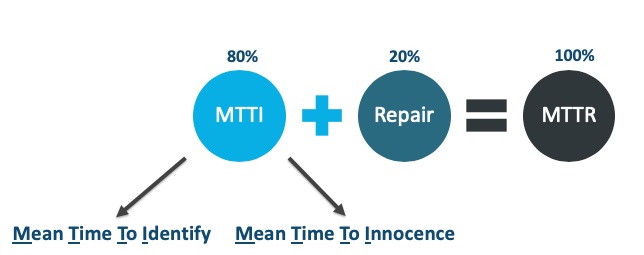
For example, in the case of a slow application where all fingers are pointed to the network, the team spends two hours, give or take, investigating the issue. Then, as suspected, the network team finds that the issue definitely does not stem from a network problem. In fact, everything is running perfectly from the network perspective. Now, the application team steps in to troubleshoot. While the network team didn't spend any time on repair, they still burned a couple of hours dealing with the situation. Fixing a problem isn't what takes up the most time, it's finding the needle in a haystack that is the real issue, which can take hours or even days.
Through automation, network engineers can reduce their MTTR dramatically by effectively reducing the time it takes to identify the needle in the haystack, mapping out every single network dependency automatically, without having to rely on out of date or incomplete manual network diagrams — and better yet, they can finally prove that a problem lies outside of the network with accurate maps.
As today's networks become more complex, and software-defined, it's simply not enough to just use manual diagrams and simple tools such as traceroute when attempting to navigate and map a critical path of applications or find the source of a problem. Instead, IT teams should leverage an enhanced path-mapping tool powered by automation. Such a tool would calculate the desired critical application path by analyzing access lists, NAT, policy routes, and other networking elements not included in the standard command line tools. This is an effective way to map specific protocols and applications across a network, finding asymmetrical paths, and collecting layer two and three data. In short, this technology enables you to immediately map out different application flows within your network and help you proactively understand where to go in the event that something fails.
However, this type of tool is most valuable when it can be applied to a larger abstraction of network documentation. Completely automated documentation allows network engineers to document their entire network on-demand and create dynamic maps that update automatically each time there is a change to the network. There's no better way for network engineers to make a clear and concise case that the network is innocent than by showing this on a map that is easy for everyone to understand.
A map is also a powerful collaboration console between network and application teams. Traditional network diagrams have hampered effective collaboration among teams in the past, as they become obsolete quickly and too often are incomplete. But with data-driven dynamic maps, each and every element on the diagram represents a live network device, with hundreds of data attributes, including its configuration file, routing protocols, neighbors and more. In other words, dynamic maps are not just a diagram, but a shared forensics console with virtually infinite detail that is accessible to anyone anywhere. This plays a huge role in a network team's ability to collaborate with application teams and easily communicate where the problem lies.
When an application isn't running properly, the first question is always, "is it a network issue?" Without the right tools, network teams could spend hours on end attempting to prove their innocence with incomplete manual documentation. But with the power of automation, network teams can cut troubleshooting time in half by gaining immediate visibility into the network — and showcasing it — with dynamic maps, including insight into how an application is flowing at any given moment.
Further, through automation and visualized, contextual network mapping, network and application teams can better collaborate, bringing the strengths of both teams together, instead of pitting them against each other. By breaking down silos, both teams can be running optimally more of the time, ensuring greater efficiencies across IT departments, directly supporting an organization's bottom line.