Let me explain.
It's a time-honored tradition to drag ticketing platforms through the mud. There's no easier blog to write than the one that bags on an entire industry for pricing, fees, and a monopoly on live events. The president is even getting in on it. True or not, that's not my purpose here.
I want to talk about software testing.
Look, no matter how you think about online ticket brokers, what they're trying to do is really hard. I'm not talking about their business, events management, artist contracts or any of that. I'm talking about the logistics of creating a software platform with ultra-high-volume ticket sales that come in dramatic bursts.
The event covered here occurred at the intersection of three different kinds of testing: performance, security, and chaos. I've never worked or consulted for a company where these were done by the same team — folklore has it that the teams doing this testing generally don't even work directly with the people responsible for the areas they're testing!
Each of these is a career path unto itself. Many books have been written, and much venture capital has spilled into companies centered around them.
Why don't they talk to each other?
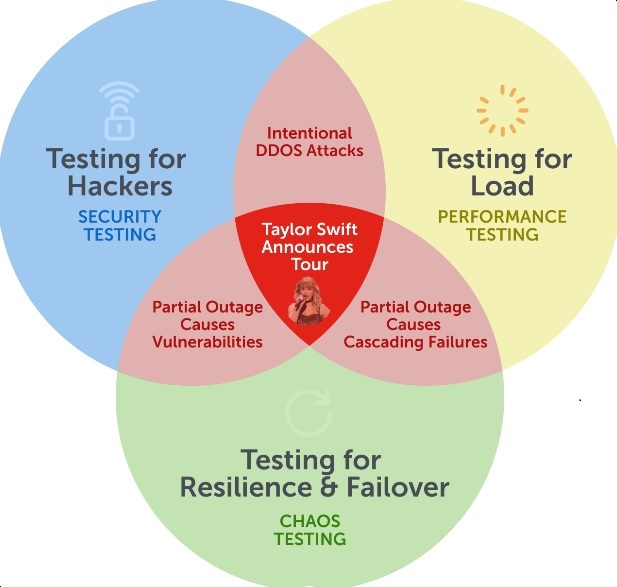
It's important to understand the convergence of these disciplines, lest you live in perpetual fear of the Swifties.
What Happened
On November 1, Taylor Swift announced the Eras Tour, her 6th world tour, commemorating the release of her 10th studio album. Presales tickets popped up on a major ticketing site, which promptly groaned, creaked, and fell over. Fearless Swifties hammered the site without mercy, and as the small Utah theme park called "Evermore" found out, that can be a problem.
Unlike the decidedly low-tech method available to me when I bought Van Halen tickets from the grocery store in 1989, the whole world is now standing in the same virtual queue, and even the most durable cloud architecture can't handle this level of deluge.
People will abandon a brand in a flash when they don't have a good experience, so when they don't have a choice about where they get their tickets from, they turn to the best tools they have (TikTok, Twitter, and Instagram) for their outrage.
We Are Measured In Uptime
Your reputation is measured in 9s. If you have "3 9s of reliability," your site is up 99.9% of the time. In the early 2010s, this was the gold standard, even though it meant you could only be in the red for 8h 46m in a year (about 10 minutes a week). This was the early days of cloud computing, distributed architecture, regional failover, and SRE.
Now, 4- and 5-9s is the standard — you don't even have seconds before Reddit sees hundreds of angry posts. The average Taylor Swift lover doesn't care if you have 99.999% up-time (5:16 of outage per year). The only time Swifties are even looking at your ticketing site is during that 5 minutes of outage!

That is a very powerful, very loud, very large group of people to be angry with you all at once. This isn't just ticketing platforms — it extends to game releases, the newest iPhone, Marvel movies, mortgage interest rate changes, bank runs, toilet paper hoarding and many, many more.
Performance Testing
Any time you have a large number of requests sent to a service with finite resources, you risk it being overrun.
Not just API-based performance testing, but also functional performance testing, preferably with multiple browsers and mobile devices, done from multiple data centers around the US (or around the world) to ensure you can cover traffic with different latencies, different geographic origin, etc.
Most performance testing seems to be done from internal infrastructure, and this is where I would urge you to rely on cloud providers to give you the diversity of region, machine type, and device. It also requires deep monitoring and error reporting to be embedded into production systems.
Security Testing
Once hackers get wind that a site is down for one reason, they can look for open pathways to attack other parts of the system. They can even start to anticipate this when they know that particular businesses are regularly brought down by large traffic volumes!
And this isn't just penetration and hacker testing, but also DDOS testing, and making sure your systems are resilient to more than code attacks. When a microservice is brought down by an attack, it can be like an open pipe — one that runs in both directions. You need to make sure a partial system outage doesn't render the rest of your system open to unintended uses of your APIs.
Chaos Testing
This issue is related to chaos testing because, well, it's right there in the word: a situation arises where not only do you not control, but also you don't even know what's going on in various parts of the system.
Chaos testing isn't as widespread as it should be. Companies that do have dedicated teams and infrastructure enjoy a level of confidence in their system that inspires envy in others, but they also tend to work in isolation. If they have their own environment, segregated from the dev/test environments, it's often not known how their work can apply to other teams (unless they uncover something huge). They need to work with Security and Performance testing teams to make sure that systems can expect the unexpected, and that failover systems work as designed.
Conclusion
This issue is related to all three of these disciplines because you simply can't cover this with a single methodology. People tend to think of QA as one monolithic blob of overlapping skill sets, but there are significant differences between the craft, the threats, and the risk profile covered by each. I can't give you the recipe for how to fix it, except to say that it's going to depend on your particular situation, and the human element of how your teams communicate. Risk modeling for this needs to be hyper-collaborative.
This requires strong executive leadership, as well as a good understanding of the blast radius of these failures. It's not only very difficult, but until recently I'd argue that it wasn't possible.
My advice to all these teams: get into a room together and speak, now, unless you want these headlines to keep waking you up on random midnights!
Thank goodness BTS is on a break — now you have some time to prepare; though I hear Harry Styles has a lot going on …