In Part 1, I showed how traditional APM solutions fail to provide reliable visibility into application performance because they rely on head-based sampling.
Start with APM in a Digital World - Part 1
The probabilistic and random nature of head-based sampling was good enough for legacy monolithic applications because of their predictable performance patterns. They ran with code in a single unitary system without being subject to frequent changes. While head-based sampling was fine in the monolithic world, it is not suitable for today's digital environments. In the cloud-native world, it is imperative to follow every transaction, including the long-tail anomalies, for delivering a consistent and flawless end-user experience.

Evolution to Cloud-Native
While it's generally understood that cloud, containers, and serverless, as well as DevOps practices, are the main enablers of microservices, there hasn't been much talk about how application instrumentation has to evolve to support the new requirements of speed and scale in the cloud-native world.
The value proposition of traditional APM was to simplify data collection via bytecode instrumentation using vendor-specific agents. Like head-based sampling, legacy APM agents worked well for monolithic apps, but are becoming increasingly irrelevant and, in many cases, inadequate for the cloud-native world.
Our conversations with customers and prospects have revealed a clear pattern of shortcomings of the traditional instrumentation approach. Next, we lay out the critical capabilities missing from the current APM solutions to become microservices ready.
Traditional APM Agents Are Not Based on Standards
When legacy APM agents were created, there were no industry standards on instrumentation to enable distributed application visibility. Each vendor created proprietary agents resulting in vendor lock-in.
Today, open-source implementations such as Zipkin and standards such as OpenTracing and OpenCensus have emerged to address visibility into distributed systems in a vendor-neutral way. Open standards enable flexibility and choice by keeping the code instrumentation portable and interoperable, thereby de-risking your investments.
OpenTracing is an instrumentation standard for application developers and OSS library maintainers to instrument code without locking into any tracing vendor. OpenTracing, in particular, is gaining traction under the governance of Cloud Native Computing Foundation (CNCF).
Open standards enable you to leverage the innovation from the broader community without getting tied to a particular vendor. For instance, traditional APM vendors typically take weeks or months catching up to the newer versions of OSS frameworks.
Most of the popular frameworks come instrumented out-of-the-box by the community or service owners. That means you don't have to wait for APM vendors to catch up to the newer versions.
Bytecode Instrumentation is Rapidly Becoming Irrelevant
As applications have evolved from monoliths to microservices and serverless functions, bytecode instrumentation is often no longer needed or cannot be even used, for example:
■ Languages such as Golang compile directly to machine code rendering bytecode manipulation irrelevant.
■ In serverless environments such as AWS Lambda, Microsoft Azure Functions, and Google Cloud Functions, you do not have access to the runtime so the agent-based instrumentation cannot be used.
■ Most popular open source frameworks and libraries such as Spring Boot, Kafka, and Cassandra are instrumented out-of-the-box.
■ System-wide observability solutions such as service mesh minimize the need for developers to instrument their code. Service mesh observes every microservice interaction via sidecar proxies.
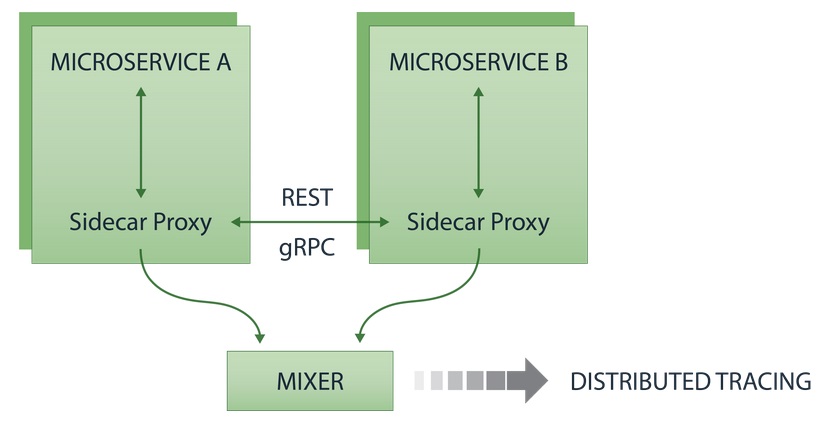
The proxy creates trace IDs and propagates the trace throughout the entire distributed system across service boundaries. Service mesh can, therefore, create distributed traces with minimal instrumentation — or the need for heavyweight APM agent.
Legacy APM Agents are a Misfit for Containerized Environments
Modifying the instruction set for every single method via bytecode manipulation can result in significant overhead — so much so that APM vendors implement circuit breakers to limit the instrumentation.
This approach worked for applications where a monolith was deployed on a unitary system using bulky J2EE application servers — and where a 2-3% APM agent overhead and few hundred millisecond latency spikes went unnoticed. The infrastructure was static. VMs and bare-metal servers used to run for months.
In today's cloud-native environments, enterprises are running microservices on tens and sometimes hundreds of containers on a host. Every millisecond counts when it comes to delivering a flawless end-user experience. The heavyweight agent-based approach doesn't work in ephemeral and dynamic container environments.
Traditional APM agents take a few minutes to initialize and send data to APM SaaS services. This will result in minutes of unpredictable blind spots every time a container restarts.
According to Gartner, Inc.:"Microservice-based applications are highly complex and dynamic, and they generate large volumes of data. This renders traditional monitoring approaches inadequate at best and dangerously oblivious at worst. Traditional APM tooling methods, such as bytecode instrumentation, have several issues:
-Significant agent overhead at runtime and heavy-lifting efforts at deployment time.
-They are unsuitable in the increasingly common polyglot approach of using whatever language is best-suited to the service because many of these languages don't support bytecode."
Proprietary APM Agents Inhibit DevOps Practices
In the pre cloud-native world, development and operations were siloed practices where developers dealt with software and operations dealt with hardware. In the cloud-native world, where hardware is in the cloud, development and operations are intertwined and share the responsibility to run applications reliably.
The traditional agent-based approach leaves developers in the dark as their code gets manipulated at runtime using a proprietary agent. Developers lose the visibility into what code exactly is getting executed in the production environment.
The open-standards approach provides transparency, better collaboration, and accurately captures developers' instrumentation intent. In the modern, cloud-native world, SREs and development teams collaborate for observability. Traditional APM's throw-it-over-the-wall approach simply does not work in the cloud-native world.
Next Generation APM Needs to be Based on Open and Flexible Instrumentation
In the cloud-native world, data collection has been commoditized. It comes out-of-the-box by leveraging technologies such as service mesh, and is standardized by open, vendor-agnostic specifications. The value of APM has been shifted to analytics.
According to Gartner, Inc.: "Instrumentation is not the key value of an APM solution. It is time for instrumentation to reach a further degree of commoditization so that enterprises can prevent agent duplication and overlap due to the tight coupling between an agent and a specific APM solution"
For APM to get microservices-ready, it needs to supplement the bytecode instrumentation approach with modern, and vendor-neutral system-wide observability approaches.