Across the globe, there is a growing trend of companies taking steps to reduce their carbon emissions and take a stand on climate change. Many companies in the US are currently lobbying Congress to take steps towards improving climate change strategies. In Europe, companies are fined for high carbon emissions, carmakers are facing a potential 39 billions in fines if they do not meet the new EU carbon emission regulations. Moreover, countries that are a part of the EU are now held responsible for their carbon footprint and are facing significant fines. Ireland, Europe's data center capital, with Amazon, Google and Microsoft sitting operations there, is expected to be fined $250M, as their data centers grow exponentially. Every business has the responsibility to do their part against climate change by reducing their carbon footprint while increasing sustainability and efficiency.
Harnessing optimization of IT infrastructure is one method companies can use to reduce carbon footprint, improve sustainability and increase business efficiency, while also keeping costs down. Even if a business is using the cloud (private or public) it still relies on data centers somewhere in the world. These consume a huge amount of energy and are quickly turning into the new frontier in the fight against climate change.
Data centers remain as a critical piece of business infrastructure as businesses seek to become influential players in today's data-driven economy. While climate change activists are focused on limiting emissions from automotive, aviation and energy sectors, the communication industry is on track to becoming a leader in generating carbon emissions.
Every second of the day, we are generating outrageous volumes of data. The energy required to process and compute all this data makes cloud and data centers among the biggest culprits in carbon footprint and electricity consumption. Worldwide data traffic is increasing 61% per year and is on schedule to reach 175 zettabytes within five years. That's an awful lot of zeroes (21 to be exact). Processing and transporting all this data across global digital services requires massive infrastructure. In order to remain sustainable, business leaders should be focusing their attention if they want to make the change. You don't want to sacrifice the performance or functionality of your data center, but you do want to increase their efficiency and performance. Increasing the infrastructure performance helps businesses achieve better profit margins leveraging better business operational efficiency through dramatic cost reductions.
Underutilization is an environmental and a business problem. Businesses underuse their data center and cloud resources in an attempt to ensure optimal performance under every conceivable scenario. They take precautions to avoid a decline in quality of service regardless of the demand at any moment. The result is bloated costs for the business and an unwarranted assault on energy resources. It's extremely costly across the board.
In this sense, data center optimization should be your first priority. That means those with existing data centers should be looking at how their IT infrastructure can be optimized to reduce power consumption while improving performance of their servers. Those who do not own their own data centers or using the cloud should make it a point to look for solutions that help optimize their instances as much as possible to do their part in the global fight against climate change.
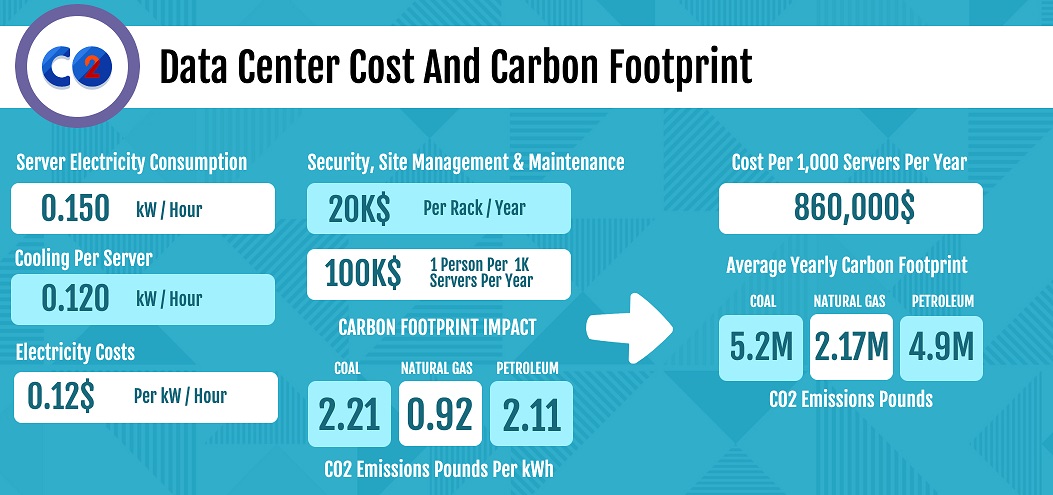
Private data-center and cloud servers operate 24/7/365. Each consumes a relatively small amount of electricity, but when multiplied by the thousands per data-center, then by the millions across the entire population of data centers, the energy burn rate really heats up. According to the International Energy Agency, data centers already account for 200 TWh per year in energy consumption — no less than 1% of the total electricity demand worldwide.

That's not even the worst part of the story. Most of the consumption is actually devoured by machines that aren't even creating any value! Across all verticals, servers and processors are dramatically underutilized or misutilized — that is, there is far more capacity whirring away than is actually being used. While underutilization estimates vary, according to Computer Economics, nearly 80% of production UNIX servers are utilized at less than 20% capacity, and over 90% of Windows servers are utilized at less than 20% of their capacity while still drawing 30 to 60 percent of their maximum power.
Across all verticals and users, the cloud is also left idle and is dramatically underutilized. While underutilization estimates vary, the University of Michigan says data centers are just sitting around doing nothing for 96% of the time. If you were to compare this to the aviation industry, this would be equivalent to 96% of flights worldwide taking-off empty, only to serve the contingency of a sudden and rare rush of passengers.
It is costly for businesses and for the environment to store and maintain both utilized and underutilized servers. Even at the thinner end of the wedge, you're looking at significant operational cost along with a dramatic carbon footprint.
There are many actions that can be taken to alleviate the outrageous waste in costs and vital resource consumption. Here's a quick and obvious technical one: DevOps can attempt to increase the utilization by better resource matching between the infrastructure and the application. This can be achieved through better infrastructure provisioning, sizing and placement policies and tools. A more intelligent approach to resource matching directly leads to more efficient use of the infrastructure, reduction in the amount of compute resources required and thus less energy.
But the leap forward lies in technology. Businesses now have a technological solution that simultaneously increases utilization AND performance. That is, they can boost utilization of current servers while improving SLAs. New applications of Artificial Intelligence are now able to learn about the resource usage patterns of applications and the processing of data in real-time, and can make application-driven decisions regarding efficient usage of resources. With AI, utilization rates can be boosted dramatically, cutting down on the size of those idle processors and server farms in the data center and in the cloud.
It's one of those rare occasions where you can do good for your business, while simultaneously — well, saving the world might be taking it a bit too far, but at least actively contributing to its betterment.
In short, an effective and relatively easy route companies can take to reducing their carbon footprint is infrastructure optimization. It's hard to grasp, but the effects of data center optimization, if action is taken around the world, is colossal. Other than stopping air travel, or factories, no other one-step offers such an immense award. Thus, infrastructure optimization should be at the top of your to-do list. Limiting the effect of your business on the environment and sustaining that limitation will ensure that, business-wise, you will reap the rewards further down the line.