Organizations recognize the value of observability, but only 10% of them are actually practicing full observability of their applications and infrastructure. This is among the key findings from the recently completed Logz.io 2024 Observability Pulse Survey and Report.
According to the survey, for the third year in a row mean time to recovery (MTTR) is increasing; taking over an hour for 82% of 2024 respondents (up from 74% in 2023, 64% in 2022, and 47% in 2021). Clearly, whatever organizations are doing is not enough to resolve their production issues or reach their SLOs efficiently.
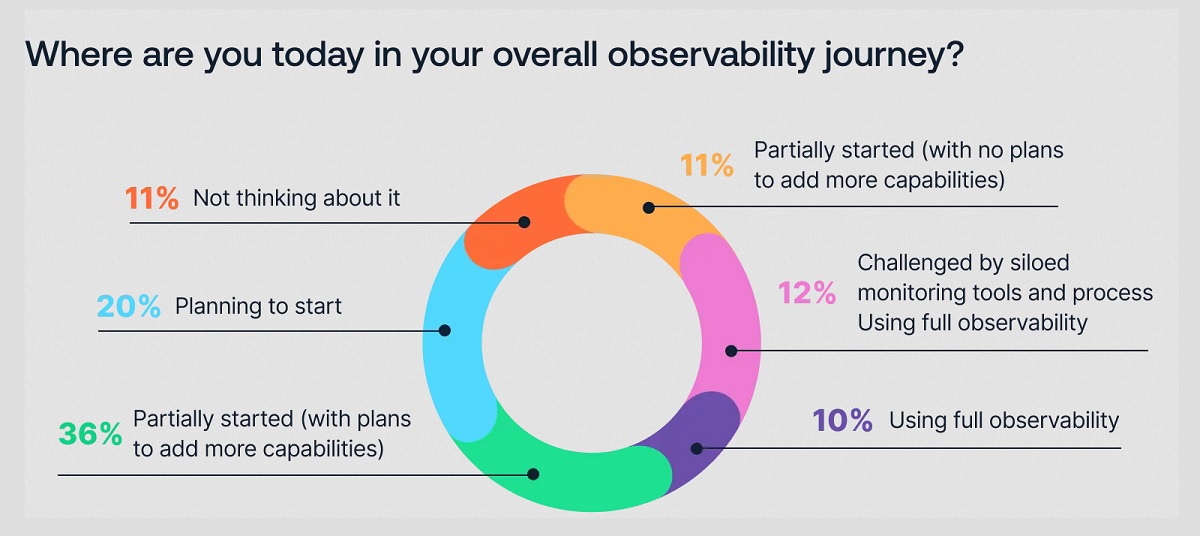
As previously mentioned, 10% of organizations that recognize the value of observability are actually practicing full observability: that is most certainly a low number. But we found that 60% of teams that are increasing their focus on observability are reporting improved and accelerated troubleshooting.
So why aren't more organizations prioritizing a strong observability strategy?
Challenges to Full Observability
One complicating factor is the increasing volume of tools and data. This may add to the complexity of a successful observability plan, but the expertise of the people deploying the plan is the biggest issue according to the survey. Lack of knowledge on the team ranked as the top challenge as the tech talent gap is impacting 48% of survey respondents.
Not surprisingly, costs are a primary concern for organizations — 91% of respondents, in fact. As they move toward full observability of their systems, data volume is multiplying, especially for those running Kubernetes in production. Monitoring and troubleshooting their Kubernetes clusters was the top challenge for 40% of respondents deploying them.
Organizations are responding to this huge increase in data and the subsequent expense of that data by adapting their observability practices to keep costs down. Exploring ways to gain better visibility into monitoring costs (52%) and working to optimize the volume of monitoring data (37%) are tactics being used in an effort to reduce observability costs.
Trends in Observability
The survey revealed some noteworthy trends in the tools being used and the approach being taken to reduce MTTR.
Consolidating services appears to be on the rise, and simplifying environments could be a way to improve MTTR. With this strategy, 28% of organizations surveyed are embracing a shared model for observability and security monitoring, a 13% increase over last year.
The big news here, however, is that 87% of respondents said they are using some form of a Platform Engineering model with 10% saying it's in the works. With Platform Engineering, a single group enables observability for all involved teams. Platform Engineering is definitely a trend that is on the rise industry-wide.
Other trends revealed are the use of data pipeline analytics as a means to address observability costs and complexity; this was noted by 75% of survey respondents. In terms of the tools being used, the majority of organizations are using between 1 and 5 observability tools currently. OpenTelemetry adoption is increasing, with 76% of respondents using the open source project as a framework to assist in generating and capturing telemetry data for their cloud-native software.
Grafana and Prometheus were the top two open source systems, 43% and 38% respectively, chosen for observability. Although it's important to note that in 2024, 21% of respondents said they have consolidated to one tool, up from 16% last year. This is an interesting trend we're definitely keeping an eye on and are happy to be a part of.
As organizations continue to adopt cloud-native technologies and face growing complexity paired with skyrocketing costs, unified, business-centric observability is becoming a must-have strategy for not only ensuring the smooth operation of their applications and infrastructure, but for meeting service level objectives (SLOs) that impact the bottom line.
Methodology: This is our sixth year running this survey (previously named the DevOps Pulse Survey) in which we engaged with 500 respondents about their observability journey. Developers, DevOps engineers, IT professionals, and executives from around the globe all chimed in to give us a glimpse into their organizations' observability efforts; the goals, the challenges, and the realities.