Most business executives are worried about the competition taking them down. What they don't realize is, their own IT can do an equal amount of damage. Imagine this: if your rideshare app is constantly down, would you rather wait for it to come back up, or would you use the "other app?" Without realizing this fact, most organizations are one high-profile incident away from losing a lot of their customers.
A Silent Business Killer
With "digital native" businesses' complete reliance on IT, whether it is private data centers or cloud-based solutions, any long, unplanned downtime can kill a business quickly. The unplanned IT downtime is costing their businesses more than they think and the business executives are not fully aware of this.
Unplanned downtime can kill a business quickly
In a recent (2019) survey of 1000 businesses, ITIC estimated that for 86% of businesses, an hour of downtime will cost the business close to $300k an hour. And, for nearly 1/3 of the businesses, it will cost them between $1 million to $5 million. On average, an unplanned service outage lasts for four hours. And, on average, two outages are expected per enterprise, per year. All this means is that an enterprise can expect to lose between $2.5 to $40 million per year when the work stops due to an unplanned IT outage. And these numbers are going up by 30% YOY.
While these numbers (which are purely based on opportunity lost, lost employee productivity, and IT recovery and restoration costs) are mind-boggling, it doesn't even include any litigation, fines, penalties, non-compliance issues by regulatory bodies or even the brand hit, lost loyalty, or customer sat/attrition issues any enterprises will take due to unplanned downtime.
While large enterprises have specialized SWAT teams to reduce this impact, the smaller enterprises feel the brunt when such an event happens. When SRE teams, NOC/SOC teams and engineering teams are pulled into war rooms to solve the problem, the development/innovation and sometimes critical operational work come to a standstill. CIOs and other IT executives get involved until critical P1s are resolved, taking their time away from other strategic work.
Components of an IT Issue Resolution
Fixing any unplanned downtime consists of three major components:
1. Identifying the problem
2. Fixing the problem
3. Get the systems back up and running
While #2 can be minimized by having skilled IT staff, and #3 can be solved by a combination of automation and skilled IT staff, #1 is part art and part science. For most organizations, this is the hardest part and the silent killer. They spend too much time trying to find out the root cause of the problem. If you can't find the problem, you can't fix it. The very thought of having long, drawn-out war-room meetings, for critical P1 issues, should be any CIO's nightmare.
The efficiency of any ITOps team is measured by two major KPIs: MTBF (mean time between failures) and MTTR (mean time to repair). MTBF is a measure of how reliable your systems are, and MTTR is the true measure of how long your service is down, costing your business. The faster you find the problem, the faster you can solve it.
Is the "Zero-Downtime Unicorn" Just a Fantasy?
Zero unplanned downtime conversation has made its way to the board rooms now. According to the Vanson Bourne/ServiceMax survey of 450 IT decision-makers, zero unplanned downtime has become the top priority for 72% of the organizations. More importantly, boards are willing to approve additional funding, outside of the IT budget, to make this happen due to the pressure from business executives. But, just having the funding is not going to solve the problem. You need the right tools to help with that process.
In order to close the downtime gap, you need to know when your services will be going down or find out what is causing the problem as soon as a service goes down. The existing tools and data collection are mostly reactive measures, so the teams scramble after the service goes down. I discussed the need for root cause analysis and identifying issues before they happen in my earlier Forbes blog.
Why is it Complicated?
There are a few critical reasons why a lot of organizations are struggling with identifying the root cause of a problem:
1. IT has gotten more complex
2. IT budgets are getting crushed
3. Most IT organizations are siloed
4. There are not enough skilled IT personnel
5. Only reactive indicators are measured by ITOps teams
While all of the above is true, it doesn't have to be complicated. Implementing a properly designed AIOps solution can solve most of this. Keep in mind, having a good monitoring solution is not the same as having an AIOps solution. One is a reactive measure and the other is a proactive measure. Monitoring can tell you what went wrong, AIOps can potentially indicate something is about to go wrong.
A properly implemented AIOps platform can aggregate and analyze data collected by many tools: Application Performance Monitoring (APM), Network Performance Monitoring and Diagnostics (NPMD), Digital Experience Monitoring (DEM), IT Infrastructure Monitoring Tools (ITIM), Security Incident and Event Management (SIEM), and log tools, which make consolidation of events across the enterprise possible.
Avoiding Alert Fatigue
Unfortunately, today's complex IT systems produce a lot of events and alerts. Most organizations also have siloed implementations. For example, it is very common for a cloud implementation to use a different monitoring tool than an on-prem implementation of the same service. This leads to uncoordinated and unrelated alerts from multiple locations for the same incident.
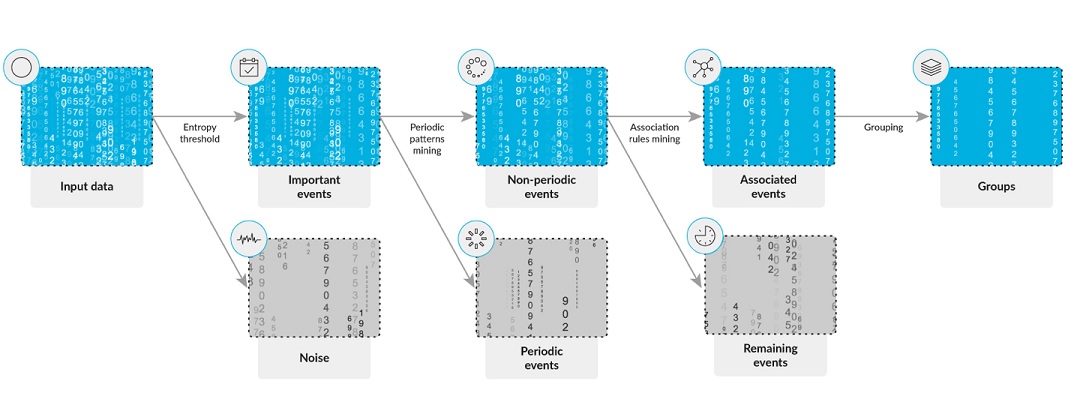
A large enterprise we worked with had an issue of getting over a total of 100k events (alerts, network events, and service tickets) per single logical incident. This created "alert fatigue," with everyone chasing everything until they found the root cause. The first step was to reduce the large stream of low-level system events into a smaller number of logical incidents. With a combination of log structure discovery and parsing, periodicity detection, frequent pattern mining, and applying entropy-based encoding with a combination of temporal association detection and network topology graph analysis (yes, all the geeky stuff), we were able to reduce the volume of the event stream by 98%.
Imagine chasing a P1 in 100,000 single-siloed information pieces vs in 2,000 consolidated, grouped, and related events.
Demand More from Your CIO
The same ITIC survey suggests that 85% of corporations now demand a minimum of "four nines" of uptime (99.99%) for critical applications from their service providers. That is about 52 minutes of acceptable, unplanned downtime per year. Yet most CIOs struggle to provide the same quality of service and SLAs for their services to their businesses.
It is time the business executives demand the same "uptime" for their services from their CIOs that the CIOs demand from their service providers.