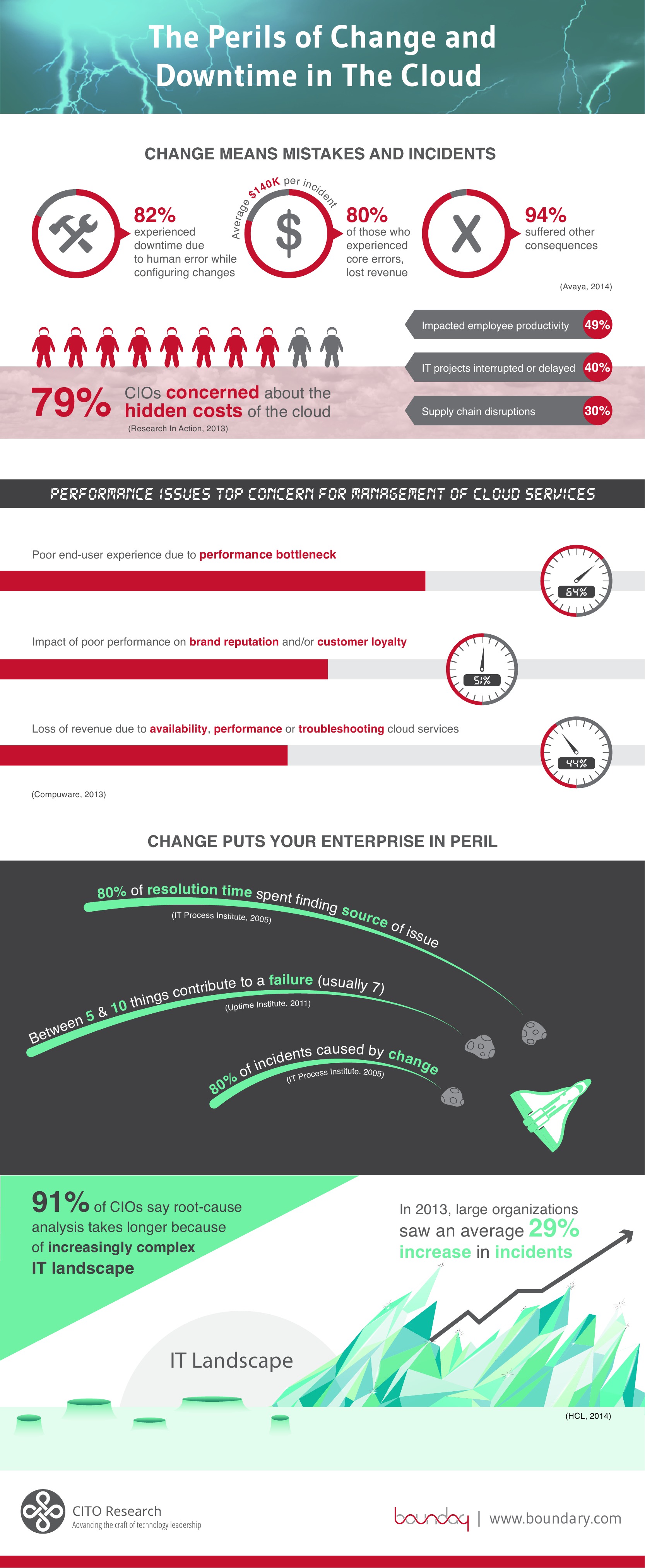
The mantra for developers at Facebook for the longest time has been "move fast and break things". The idea behind this philosophy being that the stigma around screwing up and breaking production slows down feature development, therefore if one removes the stigma from breakage, more agility will result. The cloud readily embodies this philosophy, since it is explicitly made of of unreliable components. The challenge for the enterprise embracing the cloud is to build up the processes and resiliency necessary to build reliable systems from unreliable components. Otherwise, moving to the cloud will mean that your customers are the first people to notice when you are experiencing downtime.
So what changes are necessary to remove the costs of downtime in the cloud? Foremost what is needed is a move to a more resilient architecture. The health of the service as a whole cannot rely on any single node. This means no special nodes: everything gets installed onto multiple instances with active-active load balancing between identical services. Not only that, but any service with a dependency must be able to survive that dependency going away. Writing code that is resilient to the myriad failures that may happen in the cloud is an art unto itself. No one will be good at it to start. This is where process and culture modifications come in.
It turns out that if you want programmers to write code that behaves well in production, an effective way to achieve that is to make them responsible for the behavior of their code in production. The individual programmers go on pager rotation and because they have to work side by side with the other people on rotation, they are held accountable for the code they write. It should never be an option to point to the failure of another service as the cause of your own service's failure. The writers of each discrete service should be encouraged to own their availability by measuring it separately from that of their dependencies. Techniques like serving stale data from cache, graceful degradation of ancillary features, and well reasoned timeout settings are all useful for being resilient while still depending on unreliable dependencies.
If your developers are on pager rotation, then there should be something to page them about. This is where monitoring comes in. Monitoring alerts come in two basic flavors: noise and signal. Monitoring setups with too many alerts configured will tend to be noisy, which leads to alert fatigue.
A good rule of thumb for any alerts you may have setup are that they be: actionable, impacting, and imminent. By actionable, I mean that there is a clear set of steps for resolving the issue. An actionable alert would be to tell you that a service has gone down. Less actionable would be to tell you that latencies are up, since it isn't clear what, if anything, you could do about that.
Impacting means that without human intervention the underlying condition will either cause or continue to cause customer impact.
And imminent means that the alert requires immediate intervention to alleviate service disruption. An example of a non-imminent alert would be alerting that your SSL certificates were due to expire in a month. Impactful and actionable, absolutely. But it doesn't warrant getting out of bed in the middle of the night.
At the end of the day, adopting the cloud alone isn't going to be the silver bullet that automatically injects agility into your team. The culture and structure of the team must be adapted to fit the tools and platforms they use in order to get the most out of them. Otherwise, you're going to be having a lot of downtime in the cloud.
Cliff Moon is CTO and Founder of Boundary.