The ability to view things from the end user perspective and to drill down into the code level deep dive can be extremely powerful, and the information gathered from this ability provides DevOps teams with an instant view into the direct root cause of any user experience problem they may not otherwise have noticed.
Traditional real-user monitoring (RUM) techniques provide insight into how your user actually interacts with your website or application. Synthetic monitoring, particularly when using real browsers, provides a similar assessment of expected user experience along with the benefits of true availability monitoring, third-party impact, and consistent baselining capabilities.
Combining synthetic and RUM gives a complete view of the user experience along with high level root cause clues. RUM, by itself, can miss outages, page errors, and third-party problems. Synthetic, by itself, is really only a proxy for real-user experience and can miss problems experienced by various user populations. Using both techniques in tandem eliminates those inherent blind spots and can provide an organization with the best view of their users’ experience – both actual and potential.
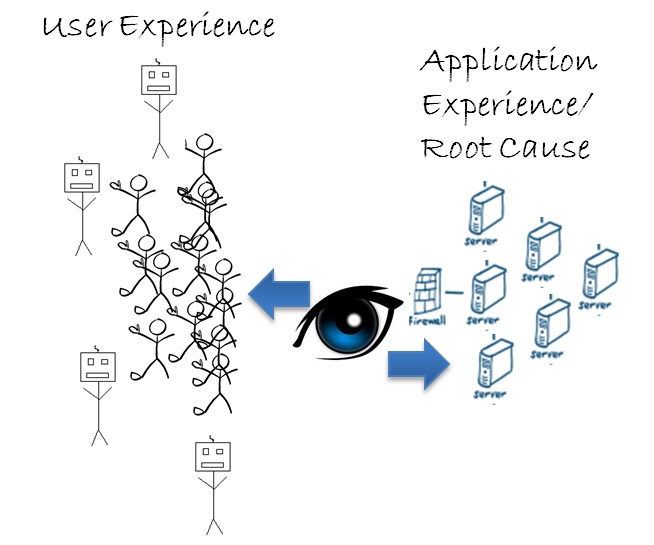
But monitoring user experience only tells you half of the story. The ability to look at things from the application/back-end perspective and drill down to the code (or up to end-user transactions) is a powerful root cause identifier. By discovering problems in delivery, DevOps teams can work to prevent or minimize user impact on their software.
Application and server monitoring provide insight into relative transaction performance. Furthermore, it provides an accurate view into the root cause of user experience degradation in your own infrastructure. These tools allow developers to identify issues before code is deployed while simultaneously giving ops teams the tools to address issues and communicate to app owners in real time. Providing this flexible view of user experience and application health provides a clear view of impact and root cause, allowing dev and ops to work together prevent and minimize damaging negative user experiences. Having all of this working together at the same time will do wonders for your overall relationship with your end user.
The ability to pivot the perspective from user experience to application transaction performance can give your organization a powerful view into user experience and root cause diagnostics. Put another way, it helps to answer the “what” along with (possibly more importantly) the “why” when it comes to performance issues. When these perspectives are seamlessly tied together and are easily available to a variety of technical and business users, the result can only be APM awesomeness!
Denis Goodwin is Director of Product Management for APM at SmartBear.