In today's fast-paced and increasingly complex network environments, Network Operations Centers (NOCs) are the backbone of ensuring continuous uptime, smooth service delivery, and rapid issue resolution. However, the challenges faced by NOC teams are only growing. In a recent study, 78% state network complexity has grown significantly over the last few years while 84% regularly learn about network issues from users. It is imperative we adopt a new approach to managing today's network experiences.
A successful network observability practice means improving operational efficiency through baby steps. There is no reason you need to boil the ocean here and rip and replace your current toolsets or processes. But the more network complexity you deal with (software-defined tech, work from anywhere, public network usage, cloud), the more you need to continually improve network operations to stay ahead of this complexity.
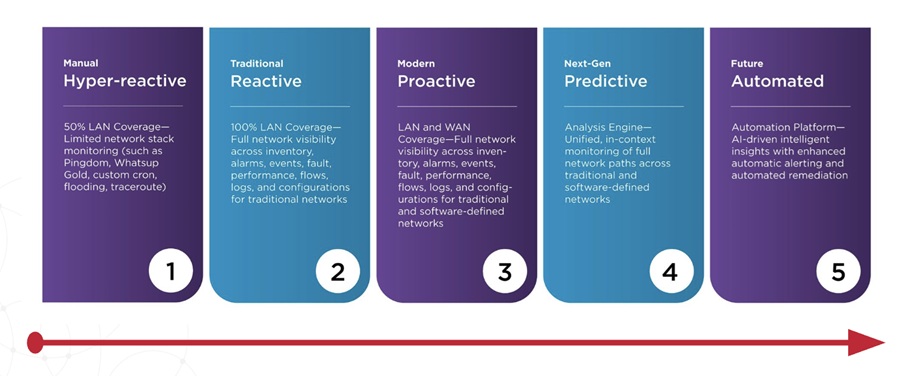
Stage 1 The Hyper-Reactive NOC
To combat swivel chair monitoring and hyper-reactive triage due to way too many monitoring toolsets, look for ways to Integrate or consolidate toolsets. 80% of orgs report a high priority to consolidate while 72% seek tight integration in their tools. Network operations with tight integration across tools have more success with NetOps.
Stage 2 The Reactive NOC
After starting the integrations or consolidations of toolsets, start expanding on the data collected and analytical features supplied by your monitoring solution to start reducing alarm noise and see the bigger picture of network device health. 57% reported they want more unified alerting (centralized alerting) while 56% say more event correlation is needed.
Stage 3 The Proactive NOC
In stage 3, network alert noise is moderate, virtual and software-defined technologies are monitored in silos by vendor-specific tools, leaving no correlation to underlay and overlay network performance. Here you should start to embrace AI-driven network observability solutions that have domain expertise in public cloud networks, WAN overlays, WAN underlays, Wi-Fi, and data center fabrics. 95% of respondents report that they don't get all of the ISP information they need to triage effectively.
Stage 4 The Predictive NOC
Here, you are doing a great job at collecting data across on-prem and public network infrastructure for end-to-end triage of network experiences, false alerts are rare and advanced analytics (AI/ML) is enabling predictive management with baselining, and anomaly detection. Consider expanding your observability into synthetics and web testing capabilities to extend visibility into public networks and an overall broader collection of data to enable proactive monitoring. Also, look to start adopting telemetry features to stream real-time events into a centralized event mgmt/analytics/reporting and automated workflows for traffic engineering, troubleshooting and network performance optimization.
Stage 5 The Automated NOC
In stage 5, you have full visibility across private and public networks to understand network performance at every hop in the end-to-end network path, advanced analytics for alarm noise reduction, configuration management and synthetic testing to evaluate the resilience of your network and public cloud and ISP networks.
Consider "low hanging fruit" network automation use cases like network configuration roll backs to known good state, enriching alarms with powerful event data or automated escalation of issues to level 2 or level 3 engineers and architects.
A mature network observability practice for your NOC maps a progression from fragmented toolsets with limited coverage to a more integrated, platform approach with coverage for modern, hybrid networks and advanced analytics. As your network operations teams progress along this model, you can shift from reactive postures where most of their time is spent on responding to and troubleshooting alerts to a proactive posture where you are detecting and resolving problems before the business is impacted.