The move to cloud-based solutions like Office 365, Google Apps and others is one of the biggest fundamental changes IT professionals will undertake in the history of computing. Microsoft Office 365 already has >70 million paid subscriptions with a goal to have annualized revenue reach $20 BILLION by 2018.

The cost savings and productivity enhancements available to organizations are huge. But these savings and benefits can't be reaped without careful planning, network assessment, change management and continuous monitoring. Read on for things that you shouldn't do with your network in preparation for a move to one of these cloud providers.
1. Don't expect to keep the network the same as when everything was on-premise
Networks will need to change with the adoption of massive cloud-based services like Office 365. When all the traffic was on-premise, internal routers and network paths may have been burdened. Now that the traffic is largely external, it will stress the network differently and have different IT infrastructure dependencies. We call it "Service Delivery Chain."
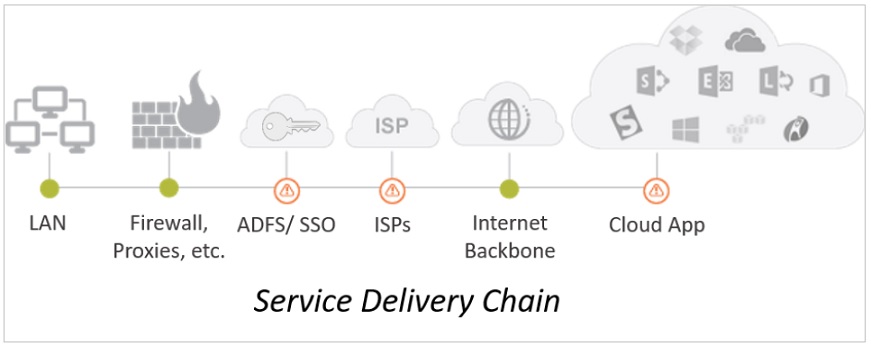
You probably thought when you adopted cloud-based services like Office 365 everything was going to be easy — just give the user a browser — but that's not the case. The Service Delivery Chain — including Single-Sign-In, Azure AD, proxies, firewalls, gateways, etc. — complicates SaaS application delivery. Especially at the branch office, for mobile and telecommuters too. End-to-end application response, uptime and availability for apps like Exchange Online, SharePoint Online and Skype for Business Online needs to be tested and measured.
2. Don't expect to keep all the firewalls and proxies just like before - they will need to change
This is a common initial desire for many mid-to-large enterprises — they want to proxy all the traffic between services such as Office 365, G-Suite and their end-users — no matter where they are. This is often seen at the beginning of migration to the cloud but it doesn't usually last or not in its initial form.
Proxying all your traffic for these services requires additional investment. It's more than likely your proxies will not be able to handle the additional load that the shift to cloud services places on them. You should synthesize and load-test the various Office 365 apps and workloads prior to and during a migration to Office 365. And you should make sure that your testing tools support proxies, single sign-on and the entire Service Delivery Chain.
3. Don't assume just because you route everything centrally, you don't need to measure end-to-end
Enterprise's may have had their own MPLS-routed networks in place for years. They put it in place back in the good old days of Exchange 2003 ;-). Then they go and believe that a decade-old network design will survive the shift to cloud/SaaS. Often, coincidental with this old network design, is their desire that they only monitor their central network because "everything just routes through to one place".
Talk about head meeting sand. If you're only monitoring from one location on the network, then you will have no idea what the experience is for end-users on the other side.
Additionally, routing everything centrally can be slow, expensive and less fault tolerant then if you sent secure, SSL-traffic directly over the Internet for branch offices and remote workers. Office 365 and wide-scale SaaS adoption for an organization places different demands on a network end-to-end.
4. Don't wait for direct data center connections like ExpressRoute for Office 365 or Azure
ExpressRoute is a new data center connection type that Microsoft has begun offering for fast connectivity from your own routed and VPN'd LAN to Office 365 and Azure tenants. Other SaaS providers often offer something similar.
Direct data center connections like ExpressRoute are still in their infancy and remain expensive. Customers still must backhaul their traffic from branch offices and other locations through their private WAN, into and out of the ExpressRoute colocation. While it sounds like it could make things simpler and faster, it does make the Service Delivery Chain longer and more complex where lots could go wrong that affects end-user experience.
5. Don't assume the problem is just going to be with the provider
The assumption that only providers like Microsoft, Google or Amazon are going to have problems is NOT a good way to start an organization's journey to wide-scale adoption of cloud services. You will have outages along the way and even post migration. The outages will occur within your own networks, your ISPs, your proxies, your Single Sign-On providers — everywhere. But with the right end-to-end monitoring and management you'll be able to quantify them and their consequences and hold each of the parties accountable for the Service Level Agreements they are signing up for.