Last week, SmartBear observed a sudden and protracted 5X increase in web page timeout errors associated with the failure of Amazon's S3 cloud-based storage service. Looking a bit more closely at our data, we dug up a few more interesting angles on the impact of the failure.
Event Timeline
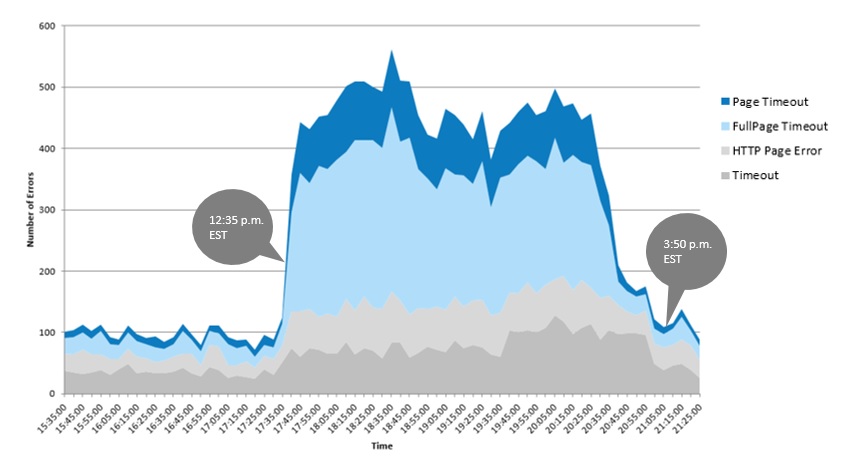
The issue hit suddenly – we saw an immediate spike in errors at 12:35 p.m. EST, and by 12:45 p.m. EST, error rates were 5X normal. For some specific types of timeout errors, the spike was more than 10X normal. At 3:30 p.m. EST, the error rate began dropping and by 3:50 p.m. EST, rates had returned to normal.
Web vs. API
The issue hit web pages hard, while API monitors were not noticeably impacted by this outage. Web pages and web apps often utilize content storage hosted by cloud services such as Amazon S3.
Common failure scenarios on Tuesday included page elements failing to load, which could cause either the whole web page to time out or specific content on a page might not render. Depending on the design of a given page, this partial content failure could be relatively minor or it could render a critical web journey non-functional. File uploads and downloads that rely on S3 storage endpoints were particularly hard hit.
In order to get a complete picture of application health, it's necessary to monitor your real user's journey through the application. The monitored user journeys that depended heavily on content hosted in S3 failed. Those that didn't have that dependency continued functioning. I personally experienced this with Slack – I was able to use the app, however files could not be uploaded presumably because these files are stored by Slack using S3 as the storage mechanism.
While far less pronounced than the spike in errors, some response time degradation was observed in API monitors that continued running successfully. Given that the issue affected Amazon's storage services rather than their hosting services for applications, this makes sense.
Geographic Impact
The issue was more acutely felt in the United States, but we observed impacts all over the globe. The spike in page errors was seen on websites dependent on Amazon S3, many of which are U.S.-hosted websites that are likely monitored from U.S. locations. Unsurprisingly, error counts spiked by as much as 25X in some U.S. monitoring locations. While not as significant as the U.S. locations, timeout and page error increases were also observed from Canada, Europe and Asia.
Takeaways
Much of the web is built on the backs of cloud providers. Most of the time, these cloud services provide a great user experience. Amazon will learn from the root cause of this issue and likely emerge from this outage more resilient than ever. It's impossible to control all aspects of these shared services – but here are three steps to take that are in your control.
1. Identify your business critical applications
2. Proactively monitor user journeys on these applications
3. Don't rely on your third party provider to tell you when it is down
It is key to utilize independent monitoring services to ensure your applications are up, functioning correctly and fast. Furthermore, missing content can be catastrophic or merely inconvenient to a critical user journey – it's important that your monitoring tool can be configured to know the difference.
Denis Goodwin is Director of Product Management, AlertSite, SmartBear Software.