If your business depends on mission-critical web or legacy applications, then monitoring how your end users interact with your applications is critical. The end users' experience after pressing the ENTER key or clicking SUBMIT might decide the bottom line of your enterprise.
Most monitoring solutions try to infer the end-user experience based on resource utilization. However, resource utilization cannot provide meaningful results on how the end-user is experiencing an interaction with an application. The true measurement of end-user experience is availability and response time of the application, end-to-end and hop-by-hop.
The responsiveness of the application determines the end user's experience. In order to understand the end user's experience, contextual intelligence on how the application is responding based on the time of the day, the day of the week, the week of the month and the month of the year must be measured. Baselining requires capturing these metrics across a time dimension. The base line of response time of an application at regular intervals provides the ability to ensure that the application is working as designed. It is more than a single report detailing the health of the application at a certain point in time.
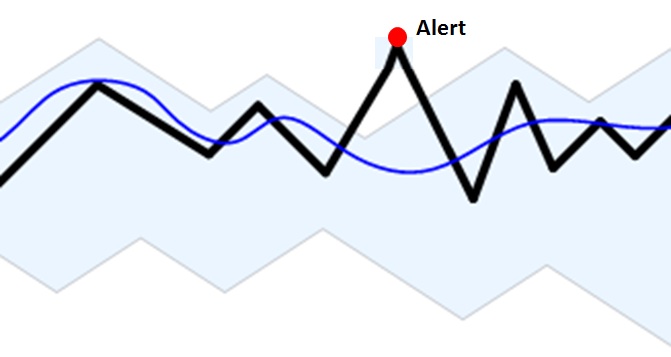
"Dynamic baselining" is a technique to compare real response times against historical averages. Dynamic baselining is an effective technique to provide meaningful insight into service anomalies without requiring the impossible task of setting absolute thresholds for every transaction.
A robust user experience solution will also include application and system errors that have a significant impact on the ability of the user to complete a task. Since the user experience is often impacted by the performance of the user's device, metrics about desktop/laptop performance are required for adequate root-cause analysis.
For example, when you collect response time within the Exchange environment over a period of time, with data reflecting periods of low, average, and peak usage, you can make a subjective determination of what is acceptable performance for your system. That determination is your baseline, which you can then use to detect bottlenecks and to watch for long-term changes in usage patterns that require Ops to balance infrastructure capacity against demand to achieve the intended performance.
When you need to troubleshoot system problems, the response time baseline gives you information about the behavior of system resources at the time the problem occurred, which is useful in discovering its cause. When determining your baseline, it is important to know the types of work that are being done and the days and times when that work is done. This provides the association of the work performed with the resource usage to determine whether performance during those intervals is acceptable.
Response time baselining helps you to understand not only resource utilization issues but also availability and responsiveness of services on which the application flow is dependent upon. For example, if your Active Directory is not responding in an optimal way, the end-user experiences unintended latencies with the application's performance.
By following the baseline process, you can obtain the following information:
■ What is the real experience of the user when using any application?
■ What is "normal" behavior?
■ Is "normal" meeting service levels that drive productivity?
■ Is "normal" optimal?
■ Are deterministic answers available? Time to close a ticket, Root cause for outage, Predictive warnings, etc.
■ Who is using what, when and how much?
■ What is the experience of each individual user and a group of users?
■ Dependencies on infrastructure
■ Real-time interaction with infrastructure
■ Gain valuable information on the health of the hardware and software that is part of the application service delivery chain
■ Determine resource utilization
■ Make accurate decisions about alarm thresholds
Response time baselining empowers you to provide guaranteed service levels to your end users for every business critical application which in turns helps the bottom-line of the business.
Sri Chaganty is COO and CTO/Founder at AppEnsure.