It is common knowledge that Data is extremely important in Automation and AIOps implementations. Good data yields good insights from the implementation. Yet, while planning for the efforts for an AIOps implementation, the effort needed for some aspects of data are completely overlooked. The most overlooked aspects of the Data are:
■ Data source: Identification of Data source
■ Data volume: availability of the volume of data needed for the implementation
■ Data Access: Getting access to the data
■ Data Storage: Storage possibilities for the data
It is somehow assumed that these are never an issue. In this write up we discuss why these are critical aspects of Data and some guidelines on how to budget for the efforts towards these in Automation and AIOps implementations.
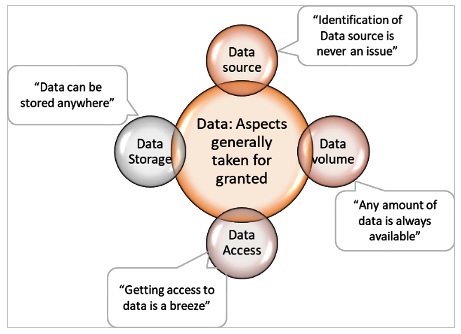
Fig1: Commonly overlooked aspects of Data in AIOps implementation
The Fallacy That Data Source Identification Is Never an Issue
This might seem like we are making a mountain of a molehill, but it is often the reason for many of the Automation and AIOps engagements to get stalled.
Where are we going to get the kind of data we need for the Project to deliver its value?
Are all the data sources really identified?
Which departments in the organization own the data that is needed for the Project. These are some of the fundamental questions on Data source that should get asked at the start of the Automation and AIOps Project. In one of proof of concepts for a Process Mining tool, getting transactional, time-stamped data was the key for the success of the engagement. We were never able to identify the source of such a data, nor identify the data source owner in the organization. As a result, the entire proof of concept had to be stalled.
But how often is it that we factor for efforts to search for the data sources in an Automation and AIOps Project?
The Myth of Tons of Data Buried Waiting to Be Excavated
Good volume of Data is always essential for any Automation and AIOps project as the insights from the data are key to the success of implementation. But it also means, that the organization should have planned for that volume of data, retained the data or should have data practices that support data updation periodically.
Often, this is not the case. If there is no specific regulation or guideline on data retention, the data is simply not available. Now, superimpose this situation with the project being dependent on this volume of data and we have a catastrophe in waiting. In one of the proof of concepts for a Service desk Text analytics platform that I was involved in, the interactions transcripts were a critical input data and this was not readily available.
There was however a workaround to get some part of the data needed. It was a herculean task to have the Service Desk interaction Transcripts specifically inserted from the Text interaction tool in order for it to be usable in the Project.
We could only get a part of the data that we wanted as the remaining data was not available. Getting through all this took time, efforts, and numerous confusing discussions. We had never anticipated this situation and hence had not planned for this effort as part of the AIOps project.
Seek and Ye Shall Get the Access to the Data — Conditions Apply!
Access to data or restriction to it, is a function of the organizational policies, security guidelines and/or the regulations governing the data based on the region it is originating from. Even a simple Incident ticket data is subject to reasonable restrictions of access. Bulk data download access is a luxury in most Automation and AIOps Projects. If the access to download is somehow available, it may be manually cumbersome to get the amount of data needed, and if not, the struggle to identify access providers is there.
It was an irony that in one of the automation Projects, we had to manually download hundreds of data points one by one, while also ensuring the meta data was downloaded appropriately with it. Hence, access to data is not something that can be taken for granted. There has to be elaborate planning on the nature of data, the region from where it is originating, from where it has to be accessed, how it has to be accessed and whether bulk access is available or not. Efforts must be woven into the project to take care of these aspects.
Put the Data in a Secure Place
It matters to customers and their contracts, whether their data is stored in — a private cloud storage or a public cloud or on an on-premises infrastructure. If the customer is from an organization subject to several regulations, it is unlikely that you can get away with storing the Data anywhere even if it is for a simple proof of concept of an Automation tool. Ensure that the Data storage is in line with that mandated by the regulations and in those regions where Data storage is permitted. If storage must be planned on an on-premises infrastructure, aspects such as procurement of the infrastructure, installations, security validations must be ensured. For this, the project should have budgeted the efforts.
Bringing It All Together
It must be clear by now that efforts for these aspects of Data- source, Access, volume and storage cannot be overlooked and must be budgeted for in the Automation and AIOps project plan. One of the best ways to do that is to plan for a stream of tasks called "Data" alongside the other streams in the Project (such as commercial, legal, process, people) and include these aspects of Data as sub streams.
It may be noted that the efforts required for these aspects of data may depend on one or more of the following parameters
■ Location spread of the Data in scope: Higher the location spread, it may be that the Data source owners would be spread too. It may be prudent to factor additional efforts for Data source/owner identification in the plan.
■ Data generated from Legacy or in-house products: Where the data is generated from Legacy tools or from in-house developed tools, it may be good to budget some efforts towards ensuring data access is available and the volume of data needed is available.
■ Data source ownership spread across Vendor/provider: Higher efforts must be budgeted towards discussions with the vendors/providers who own the data sources and for the activities to get access to the data.
■ Regulations that the organization may be subjected to: Higher the regulations, the aspects related to Data storage and Data access will need more focus.
■ Organization's maturity in the automation journey: If the organization is new in their automation journey, identifying the right use cases and building the business case for them would need sufficient efforts budgeted.
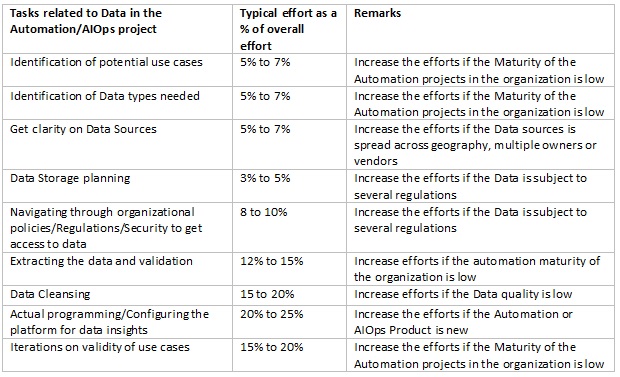
The table below is a sample guidance based on my experience of working with Automation and AIOps projects.