If you live in the United States, there’s a good chance you had no idea that the Internet turned into a wide-ranging traffic accident last week when Facebook went down for half an hour. This is because the outage occurred on Thursday morning at around 3:50 am EDT, meaning that West Coast night owls were the only group on the continent that was really affected.
Elsewhere, however, it was a different story. Due to the time difference, Europe experienced the outage during early business hours, and much of Asia saw it happen in the late afternoon, resulting in widespread website failures during critical points in the day.
Now you may be asking why a social media site experiencing problems would be that big of an issue for business. Heck, given how much people procrastinate on Facebook, one might even wonder if the outage led to an increase in productivity.
The answer lies with the massive Internet footprint that Facebook carries. Many sites rely on the social media giant for third party services like login, commenting, and sharing platforms, so when Facebook is completely unavailable, it can wreak havoc on thousands of other sites as well. We saw plenty of examples of this last week during the outage.
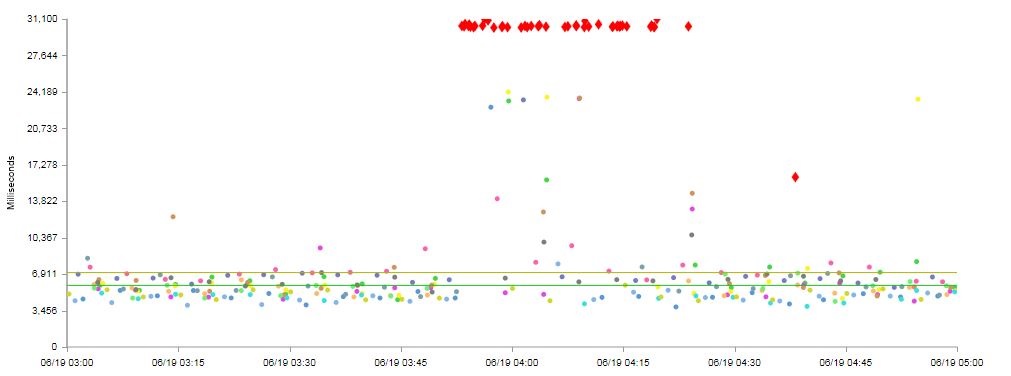
Every one of those red dots in the above graphic represents a document complete from a specific location that took 30+ seconds. Because Facebook was blocking the document complete, the user experience was dramatically impacted, resulting in many infuriating pinwheels and hourglasses spinning over and over.
This is a perfect example of what is known in the DevOps world as a Single Point of Failure (SPOF). When one component of a website can render the entire thing completely unavailable if not functioning properly, it becomes a weak link that compromises the strength of the entire chain.
From a DevOps perspective, what is needed is a detailed plan in place to serve as a backup in case the third party service goes down. In the case of this latest Facebook outage, the problem lay with the fact that many sites, rather than using the asynchronous tags that Facebook provides, were using outdated ones that block document complete. These new tags, had they been applied to the affected sites, would have prevented any bad user experience and allowed the rest of the site to continue to function normally even if the Facebook components weren’t working.
This risk is not exclusive to Facebook, however; it’s one that is an inherent aspect of all third party services. Facebook may be one of the largest providers of these services, but they’re hardly alone.
The lesson learned from this experience – and one that most European or Asian sites are likely more aware of since the outage had a much greater effect on their businesses – is to build processes that ensure that you stay up to date with vendor changes. For example, Facebook began offering their asynchronous tags in late 2012, but nearly a year and a half later, many sites were clearly not yet using them due to the widespread performance issues that we saw during that half-hour window on Thursday morning.
Facebook’s login API, however, is a separate matter altogether. While asynchronous tags will prevent an entire page from being slowed down by a single non-critical element like sharing or commenting, if your site is inaccessible without a properly functioning login system, you’re facing a much greater problem. The solution here, therefore, is to have an alternative in-house login system in place so that your site is not relying on a single third party component that is ultimately outside of your control.
Identifying a SPOF is only the first step. Once located, implementing asynchronous tags or alternative solutions will prevent the SPOF from existing, thus proving a reliable and fast website.