With the complex, dynamic nature of today's IT stack and the operational processes that support it, IT operations teams are finding they need to constantly grow their resources to manage all the moving pieces. This can get expensive … but how much are they spending?

The answer is often surprising. Complexity has made it hard to quantify how much excess resources are being wasted on simply dealing with new processes and challenges that relate to growth. Sorting through noise, filtering the signals that matter, recognizing and troubleshooting, sharing with distributed teams — all of these processes become more complex as organizations grow and environments modernize. AIOps solutions can help recoup some of these wasted resources — but how much? To understand the true cost of IT operations and the value AIOps can provide them, it helps to deep-dive into how key roles and processes in IT organizations have transformed, and how these changes are impacting the way IT operations teams need to operate.
Business Value Assessment
The key to understanding the actual cost of your IT operations lies in assessing the impact of several core metrics on your performance and processes. Along the way, you also identify where AIOps improvements can make the biggest difference and determine the actual financial value of an AIOps adoption project.
These are detailed in the following image:

■ Major incidents — their volume and MTTR help quantify your average service downtime — which basically means your Operational Efficiency.
■ Minor incidents — their volume, MTTR, and time spent on handling them — all amount to your Operational Performance in man-hours.
■ Incident management processes — determining the amount of time you spend on each of your incident management life cycle phases allows you to understand where the most improvement is needed.
■ The maturity of your tools and processes — allows you to identify how much you will need to invest in improvement through AIOps adoption, and how much value can be achieved.
■ Your headcount — identifying exactly how many people are involved in your IT operations, directly and indirectly, helps close the loop on Opex.
Closing the Gap: AIOps to the Rescue
AIOps de-risks digital transformation initiatives by allowing IT operations teams to handle the data and complexity that these transformations bring to the table. It does so by providing IT Ops with several capabilities detailed in the following illustration:
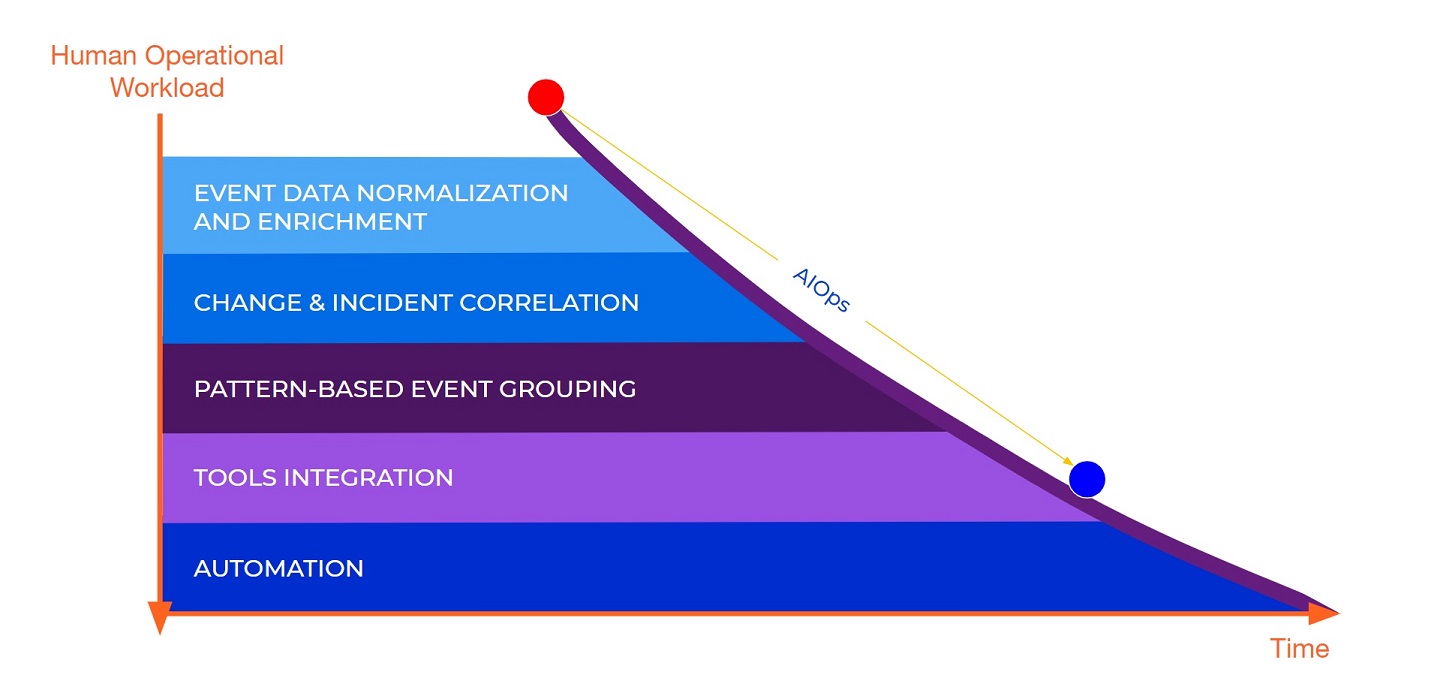
What are the quantitative values of AIOps?
■ AIOps gets rid of the noise. Whether it's multiple alerts stemming from the same problem, or a change that caused an alert storm, AIOps identifies and eliminates that noise before IT Ops spends time on it. Correlation, maintenance-based alert squelching both equate to fewer incidents. Typically, 50% or more of incidents are non-actionable noise.
■ AIOps helps quickly diagnose and identify the root cause of an incident. That means teams can start remediating sooner and with more certainty.
■ AIOps provides automation. That means everything from a unified ops console to automated incident workflow to auto-triggering of remediation actions. Overall, it means speed and accuracy for every incident dealt with or lower MTTR.
■ These benefits enable organizations to reclaim engineering time and put it to use on transformation initiatives. These also mean improvements to Service Availability.
Once you assess the actual costs of your IT operations and calculate the quantitative values AIOps can bring you — you can make an educated decision on where and how to improve.