The recent outage of the University of Cambridge website hosting Stephen Hawking's doctoral thesis is a prime example of what happens when niche websites become exposed to mainstream levels of traffic.
The widespread fame of the author as one of the figureheads of science generated a level of interest the university's web team was not prepared to handle, resulting in a familiar story: Website goes live; minutes or hours later, it crashes due to the large influx of traffic.
While it is obvious that the University of Cambridge didn't expect the level of traffic they saw, there are steps organizations and enterprises of all sizes can take to prevent this kind of digital downtime.
On Oct. 23, Hawking's Ph.D thesis went live, but by Oct. 24, the website had crashed. The release of the paper was timed with Open Access Week 2017, a worldwide event aimed at promoting free and open access to scholarly research. Though the scholarly research was made available through the university, within 24 hours of its release, no one could access it.
According to a Cambridge spokesperson, the website received nearly 60,000 download requests in less than 24 hours, causing a shutdown of the page, slower runtimes, and inaccessible content for users.
While this could be the first time a doctoral thesis invoked such widespread interest, this kind of problem, due to overloaded networks has unfolded before. In this case, it seems that the sudden increase in the number of visitors saturated the infrastructure that hosts and delivers this research. This happens when the amount of processing power required to determine what the searcher is looking for and where to send it exceeds the ability of the machines (routers, switches and servers) on the network to respond.
Organizations like Cambridge University often have limited processing power on their networks either because they build their own data centers, reducing their flexibility to respond to spikes in traffic. While each individual request may only take a fraction of each machine's resources, when several come in at once, it can slow connections, create congestion or even absolute failure.
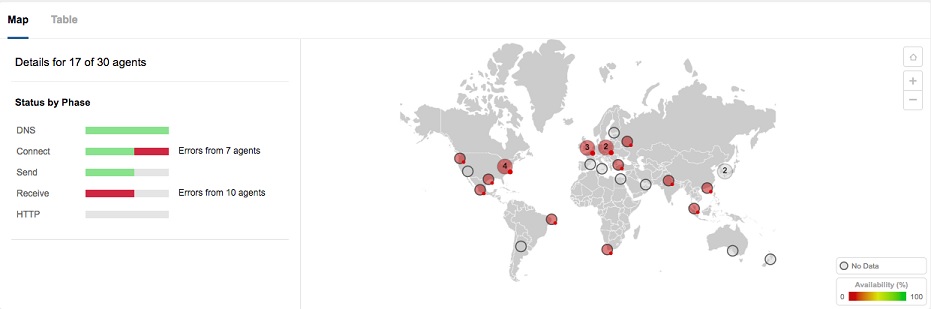
Figure 1: Global locations unable to access the Cambridge University website, with errors in the connect and receive stages.
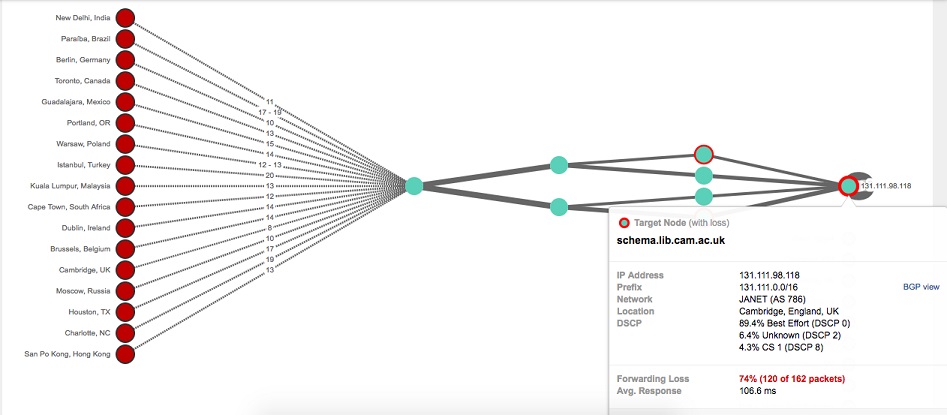
Figure 2: Traffic from all over the world terminates within the Cambridge infrastructure, as indicated by the spike in packet loss
For a web property like the Cambridge library, this is a temporary surge in traffic -- but not all websites are this lucky. The lesson is that if an organization isn't prepared, this is how a problem would manifest itself. Pre-planning for a spike would include increasing capacity on existing infrastructure. Leveraging a CDN can also help distribute the load across servers/geographies.
As you make important decisions about your company's website, there are many factors you'll want to consider, especially if you're expecting a surge (like on Black Friday or Cyber Monday). For sites that have spiky, but predictable traffic, here are a few options to help them stay online:
■ Use a CDN to serve up traffic round-the clock. This costs more but will have the best customer experience.
■ Flip on a CDN service well before known traffic peaks. If Cambridge had done this prior to releasing Hawking's thesis, they could have stayed afloat during the massive download requests.
■ Diversify with multiple data centers and upstream ISPs. If your organization has only one data center and one upstream ISP — if the ISP or their single data center goes down, your service goes with it.
■ Within the data center, load balanced network paths and web servers can also help reduce performance impacts.
The University of Cambridge may not plan to release another legendary scientist's thesis again anytime soon, but when it comes to web performance, you can have a guaranteed return if you properly prepare for your network's next big event.