In today's complex, dynamic IT environments, the proliferation of disparate IT Ops, NOC, DevOps, and SRE teams and tools is a given — and usually considered a necessity. This leads to the inevitable truth that when an incident happens, often the biggest challenge is collaborating between these teams to understand what happened and resolve the issue. Inefficiencies suffered during this critical stage can have huge impacts on how much each incident costs the business.
I recently sat down (virtually) with Sid Roy, VP of Client Services at Scicom, to get a deeper understanding of how IT leaders can more effectively size up these inefficiencies and eliminate them.
The Cost of IT Incidents
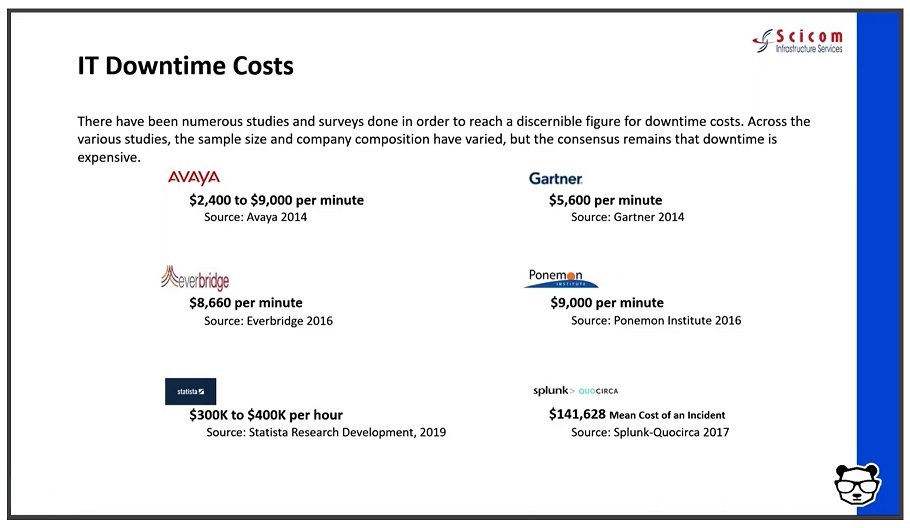
When asked what a minute of downtime costs, analysts and vendors may provide different answers — but they are more or less aligned around the same order of magnitude — several thousands of dollars per minute. And with an average of 5 major incidents a month, at an average time of 6 hours for resolution — this easily amounts to millions of dollars a year.
The three key drivers of these costs are:
Staffing and team member costs: It includes FTEs, consultants, and overhead — when other teams are pulled in to deal with the incident. For many organizations, this can include offshore incident response teams.
The direct and indirect costs of an IT incident: This includes your infrastructure or capital expenditures like software licenses for monitoring, log and event management, notification, ticketing, collaboration, etc.
The business impact of an IT incident: This is one of the most challenging and unpredictable variable costs to calculate or manage, and is often the highest of all three drivers. It includes revenue loss/delay or reduction due to a major incident and the profit or loss due to brand or goodwill impact. It also includes inefficiencies suffered by other parts of the business when critical services they depend on are degraded or unavailable.
Fragmented Teams Magnify the Challenge
The incident volume, complexity, and throughput obviously affect the number of people and time needed to deal with them and often drive more indirect costs as needed resources pile up. To save on these millions of dollars of costs, you need to be able to collaborate and lower MTTR. As mentioned above, this becomes a challenge in agile IT environments.
To help streamline operations, teams need to start asking and answering several key questions:
■ Do you have an up-to-date map of your critical services?
■ Are they prioritized by business criticality (revenue, number of customers, other supported services in the supply chain)?
■ What are the upstream and downstream dependencies of these applications?
■ Have you identified the major infrastructure and application elements in your environment?
■ Are you aligned with the owners of these systems?
■ Do you have real-time knowledge of changes being done to the infrastructure and applications?
■ Do you have monitoring gaps?
■ Which monitoring tools provide you with the best value?
Answering these questions involves overcoming fragmentation across teams of people, processes, and tools — essentially integrating ITSM and ITOM to enjoy the benefits of contextual full-stack visibility and streamlined processes within the organization.
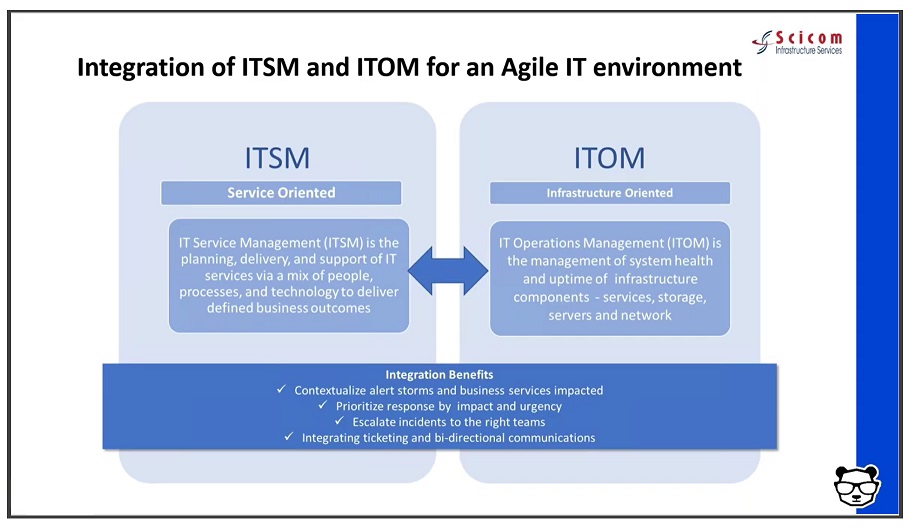
The Right Combination
What is the right combination of people, processes, and tools we just discussed? Here are the two main guidelines:
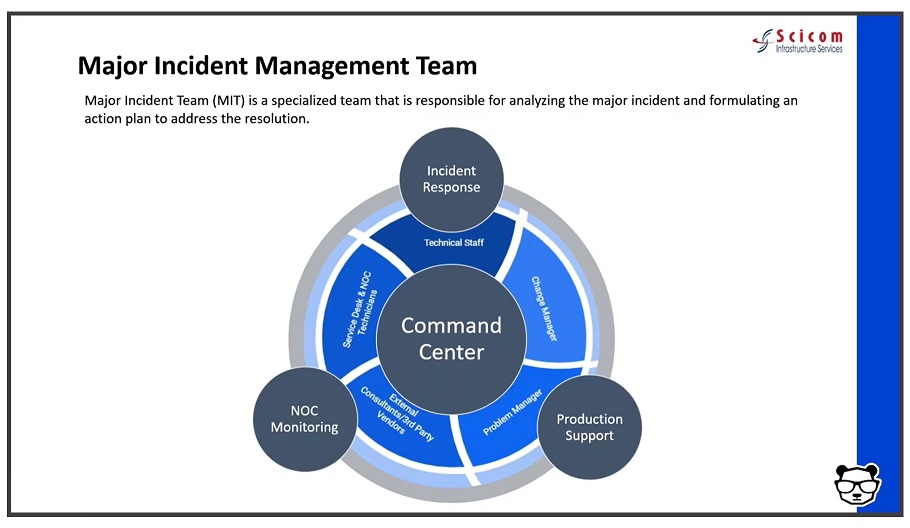
■ Set up a major incident management team- to optimally benefit from your existing staff.
This team includes three vital roles:
- The incident manager/incident response commander. A designated role in charge of declaring a major incident and taking ownership of it. Their job is to essentially stop the bleeding of revenue and costs.
- The NOC/monitoring team. This is your front line of defense. When things go bump in the night or boom in the day, they're the ones picking it up with their “eyes on the glass” — 24/7. And they're in charge of reporting and creating full situational awareness for the incident command through bidirectional communications.
- The production support. The team that actually effects the required changes and executes the remediating action.
■ Deploy event correlation and automation tools to enable the incident management team.
These tools are key, allowing your team to do all the above.
First, correlate the alerts your monitoring and observability tools create into a drastically reduced number of high-level, insight-rich incidents by using Machine Learning and AI. Add context to these incidents by ingesting and understanding topology sources as well. This creates the needed full-stack visibility and situational awareness.
Then use ML and AI to determine the root cause of these incidents, including correlating them with data streams from your change tools: CI/CD, orchestration, change management, and auditing — to identify whether any changes were done in your environment are causing these incidents.
Finally — automate as many manual processes as you can to free your IT Ops team from time-consuming tasks. By integrating with collaboration tools — you can also enable the above-mentioned bi-directional communications.