The cloud is the technological megatrend of the new millennium, creating ease-of-use, efficiency and velocity for small businesses to large enterprises. But it was never meant to be the only answer for every situation. In the world of digital experience monitoring (DEM) — where the end user experience is paramount — cloud-based nodes, along with a variety of other node types, are used to build a view of the end user's digital experience. But major companies are now depending solely on cloud nodes for DEM. Research from Catchpoint, in addition to real-world customer data, shows this is a mistake.
Bottom line: if you want an accurate view of the end user experience, you can't monitor only from the cloud. And if you're using the cloud to monitor something also based in the cloud (like many customer-facing apps), you're compounding the problem. You can't expect an accurate last mile performance view by measuring a digital service from the same infrastructure in which it's located.
This is akin to the mistake many made in the early days of monitoring: tracking site performance by measuring only from the data center where the site was hosted. That's far too limited a perspective, given the multitude of performance-impacting elements beyond the firewall. Let's take a look at cloud-only monitoring limitations and how to effectively navigate them.
How Cloud-Only Monitoring Can Create Blind Spots
For example, last year a company received alerts that its services were down. After a mad scramble to fix the problem, it discovered the services were fine, and the alerts were caused by an outage on their cloud-based monitoring nodes! The end user experience was untouched. Good news, but also proof of the noise and false positives that can occur when you monitor from only one place, and in particular, from a cloud-only view.
This led to further research. One example was a series of synthetic monitoring tests on a single request to a website hosted on AWS's Washington DC data center. The test was run from cloud-only nodes on AWS, with parallel tests on synthetic monitoring nodes running in traditional internet data center backbone locations. The test was ran starting August 1, 2018 from seven different nodes — the Washington DC AWS data center, three backbone nodes in Washington DC, and three backbone nodes in New York, NY. This consisted of over 1.7 million measurements. Here are the results.
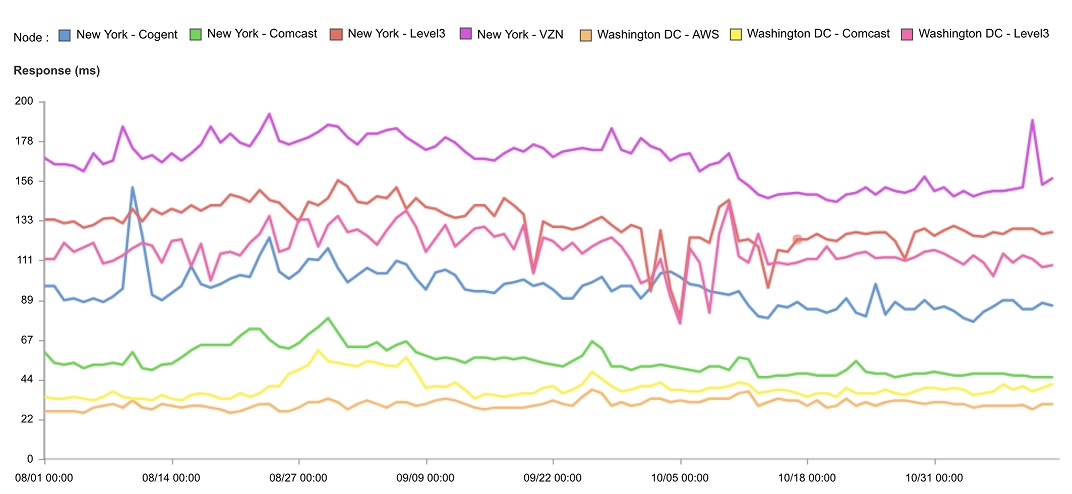
As you can see, the performance (response times) of tests run only from the cloud are faster by a significant margin. The median response time from the AWS node (bottom line, in orange) was 31ms, while the median response time from Level3's Washington DC backbone node was 117ms; and from Verizon's New York backbone node, 167ms. The cloud node measurement alone does not provide a realistic view of how end users are experiencing this particular site, and would lull an operations team into a false sense of security — not the kind of performance gap a retail website wants, particularly while we are in the critical holiday shopping season.
Why is this so? Tests run from the cloud on a cloud-located site enjoy some form of dedicated network connection as well as preferential data routing. Think of it like a VIP's cleared traffic route through a crowded city. This streamlined data path is far afield from that of an average end user, who receives his/her content after a long, circuitous route through ISPs, CDNs, wireless networks and various other pathways.
Applications Not Suitable for Cloud-Only Monitoring
Another way of explaining this: cloud-only monitoring does not track performance along the entire application delivery chain, nor does it provide the diagnostics required to manage that chain. Any single point along that path — ISPs for example — can create problems impacting the end user experience.
Important tracking processes not suitable for cloud-only monitoring may also include:
■ SLA measurements for third-parties along the delivery chain
■ Provider performance testing for services like CDNs, DNS, ad servers
■ Benchmarking for competitors in your industry
■ Network or ISP connectivity issues
■ DNS availability or validation of service
Where Cloud-Only Monitoring Is Beneficial
Of course, it's not all bad news. Cloud monitoring can provide valuable insights for certain applications such as:
■ Determining availability and performance of an application or service from within the cloud infrastructure environment
■ Performing first mile testing without deploying agents in physical locations
■ Testing some of the basic functionality and content of an application
■ Evaluating the latency of cloud providers back to your infrastructure
Conclusion and Best Practices
The key to avoiding the cloud-only DEM trap is to understand that the accuracy of your monitoring strategy depends on how your measurements are taken and from which locations. Cloud-based vantage points can be a valuable piece of the monitoring puzzle, but should not be relied upon as your sole monitoring infrastructure, as they won't be able to track the many network layers comprising the internet.
The answer will most likely be adding a blend of backbone, broadband, ISP, last mile and wireless monitoring. Start where your customers are located and work your way back along the delivery chain. By canvassing all the elements that can impact their experience you'll have the most accurate view of that experience, as well as the best opportunity to preempt performance problems before end users are affected.