Organizations are increasingly delivering critical business applications via the cloud, both public, private, and hybrid. Unfortunately, monitoring of these distributed applications and services is frequently an after-thought.
Support teams often find it difficult to be proactive in identifying and preventing problems before they occur. And since the new cloud environments are far more dynamic and complex than before, traditional monitoring architectures cannot keep pace. What is needed is a monitor that can adapt and still provide the end-to-end visibility into these applications and services, enabling support teams to be more proactive in identifying and addressing issues quickly.

Many of the organizations we work with are actively deploying service workloads and components in heterogeneous environments, often across multiple clouds and on-premise data centers. To address the challenges that emerge when these applications include deployment in the cloud, a new architecture was developed. Let's look at what this means.
The Promise of Cloud
For years, the benefits of moving applications to the cloud have been widely touted and evidence has grown that huge savings could be achieved. It is a big win to be able to deploy an app onto a single shared platform and make updates available to all users simultaneously. Users don't need to buy their own hardware or download new versions of software to get the latest features. The widespread adoption of "containerization" using Docker and Kubernetes, along with commercial "Platform as a Service" offerings, has made it even easier to move applications into the cloud.
For SL, moving its flagship product to the cloud was quite painless. The highly modular and component-oriented architecture made it a natural for deployment into Docker containers and for hosting in the cloud. (See Deploying in Docker Containers).
If only it were that easy for everyone ...
The Problem with Cloud
Given the clear benefits, why has real adoption of cloud by many organizations been so painfully sluggish? For financial institutions, eCommerce operations, logistics providers, defense companies, and many others, moving from on-premise hardware to the cloud has not been easy. Slowly but surely, the transition is happening. But, for many of these applications, data security is such a concern that large parts remain deployed in on-premise hardware kept securely behind a firewall ... and cloud is not an option.
Most monitoring systems require the use of agents that must be installed on every physical and virtual server or router, potentially introducing performance and maintenance challenges. These agents then forward all performance data to central monitoring systems, increasing network traffic. In the case of pure SaaS-based monitors, proprietary monitoring data must be sent to and stored in the cloud. This approach can introduce some real concerns, including:
■ data security
■ lack of control
■ increased monitoring costs
Hybrid: The Best of Both Worlds
The answer is found in the middle ground between these extremes. The optimal solution involves an appropriate combination of cloud and on-premise components that directly address the challenges inherent in the problem domain.
The use of the term "Hybrid Cloud" is not new. Usually, it refers to an application deployment scheme in which some application services are deployed in public cloud (Amazon, Azure, Google, etc), and others are deployed in private cloud (VMware, for example).
"Next Generation Hybrid Cloud" takes things to a new level. In such a system, all components are equally able to be deployed on-premise OR in cloud - and there is complete interoperability between all components in the system. Some services may be hosted in a multi-tenant cloud app, while others, such as sensitive data storage components, can be deployed behind a user's firewall. It is a matter of convenience or preference that dictates what goes where, not limitations of the architecture.
The problem is how best to monitor the health and performance of complex applications deployed across multiple environments using disparate middleware technologies. It boils down to what monitoring services can be shared among all users, and what needs to be completely private and secure within an organization. In many cases there are restrictions around who has access to key systems and what can be monitored. Often, it is simply not possible to migrate ALL of the components of a system-wide monitoring system to the cloud, for security reasons.
Let's explore how this modern architecture provides the most advanced, flexible, and effective solution for monitoring large-scale highly distributed applications.
Next Generation Hybrid SaaS Monitoring
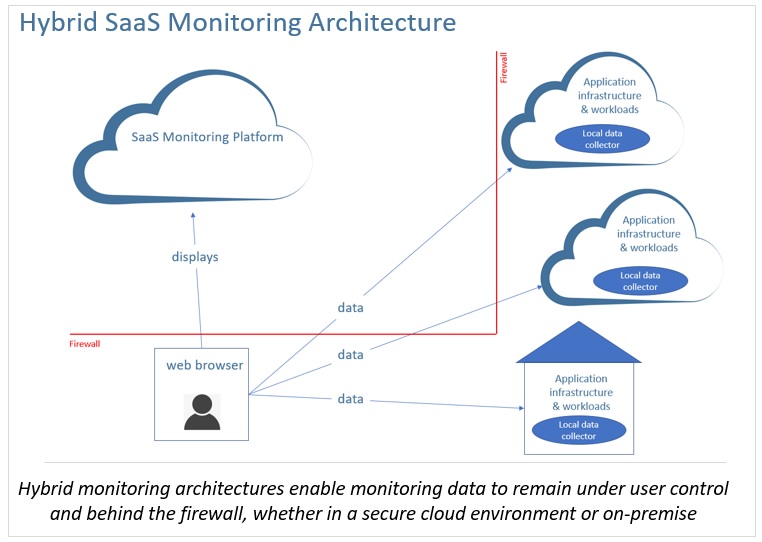
Next generation hybrid SaaS monitoring architectures use distributed data collectors deployed on-premise and in public and private clouds. Data collectors store performance data in a distributed fashion behind the users' firewallsensuring security, maintaining control of their monitoring data, and minimizing SaaS costs. No sensitive monitoring data are stored in the cloud. In-memory caching is used to maximize performance and persisted to databases as needed.
With this hybrid approach, users interact with their monitoring application via a web browser in their secure environments. Displays are served up from a cloud service and the monitoring data populate the displays, on the user's desktop or mobile device, from behind the firewall. Performance data never leave the user's secure environments.
Take Advantage of Managed Services
With a hybrid architecture like this, users can access managed services hosted in the cloud and don't have to install and maintain software to provide this capability. Updates are provided by the vendor and seamless to the user. Examples of these managed services might include:
1. custom display design and reporting tools
2. work team display design collaboration
3. custom display publishing tools
Benefits of a Hybrid SaaS Monitoring Platform
In summary, there are several benefits to this approach.
1. Centralized monitoring and visibility of applications, services, and workloads across all on-premise and cloud platforms.
2. Improved data security and control of the user's monitoring data.
3. Users can connect to both private and public data in one platform where it can be “blended” together.
4. Access to high-value managed services such as custom display development, collaboration, and dashboard publishing.
5. Reduced SaaS platform costs since monitoring data are never hosted in the cloud.
6. No need to upgrade to new versions since product updates are transparent and users are always working with the latest version.