Ever struggled to pinpoint the root cause of a network slowdown? Frustrated by alerts that only notify you when something is broken, without explaining why? You're not alone. Traditional network monitoring, while valuable, often falls short in providing the context needed to truly understand network behavior. This is where observability shines. In this blog, we'll compare and contrast traditional network monitoring and observability — highlighting the benefits of this evolving approach.
Traditional monitoring
Imagine your network is a busy highway: For monitoring, it has a few security check points and traffic cameras. This arrangement will tell you how many vehicles are on the road, and if there's any pileup on the highway or if any major network traffic congestion is noticed, an alarm goes off highlighting the issue. From this alarm, you know that something's wrong on the highway, but you have no way of knowing what it is. It could be anything from a simple traffic jam to a major accident. Figuring out the exact cause of the alarm and the resulting traffic slowdown with the help of cameras can be time-consuming.
Traditional network monitoring will tell you what's happening and nothing more.
Observability
Now, imagine instead of just a few traffic cameras, you have a comprehensive system monitoring the entire city. This system doesn't just count cars at intersections; it tracks individual vehicles, their routes, and even the weather conditions. This system is also aware of the road closures, construction, and events happening throughout the city. This is observability. It utilizes data to comprehend the reasons behind traffic patterns. In the event of congestion, the system can swiftly identify the root cause, such as a stalled vehicle on the side of a road before the congestion escalates. Observability can anticipate potential issues by detecting unusual trends, like a sudden surge in traffic in a specific location. Therefore, instead of simply reacting to a traffic jam, you can proactively tackle the underlying issues and ensure a smooth traffic flow.
Observability gives you the full picture and helps you understand why things are happening, not just what is happening.
Similarity between monitoring and observability
The only similarity between traditional monitoring and observability remains a shared goal: to gain insights into the health, performance, and behavior of a system. Both approaches are fundamentally data-driven, relying on the collection and analysis of stats like metrics, logs, and traces to understand what's happening within the system. Ultimately, the insights gained from both methods help with proactive issue detection, troubleshooting, resource allocation decisions, and more, even though the methods of investigation differ.
The bottom line is traditional monitoring focuses only on specific areas while observability involves a more comprehensive approach.
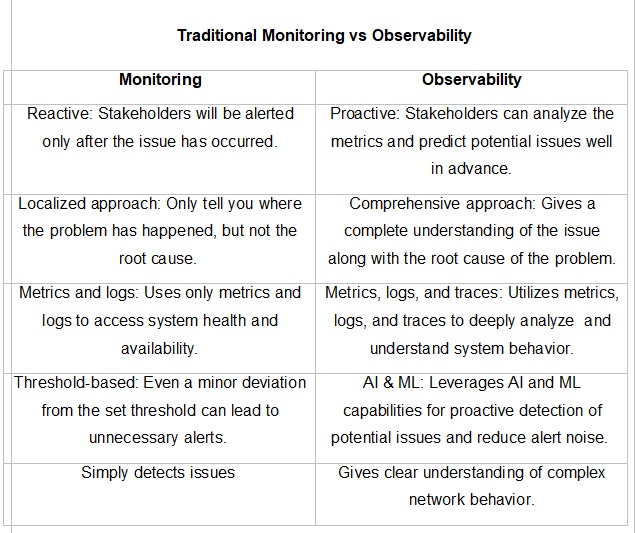
This table can best explain the difference between traditional monitoring and observability and where the former falls short:
The crucial role of observability in IT infrastructure
The evolution in IT management and observability is a response to the increasing complexity of modern networks, where traditional tools often don't have what it takes. Embracing observability gives IT admins a more comprehensive understanding of their network, leading to improved performance, faster troubleshooting, and a better user experience.
Here are some of the perks that comes with incorporating observability to improve business operations:
- Proactive issue detection and improved user experience
- Dynamic adaptation in cloud-native environments
- Adopting modern application architectures
- Log-based threat detection
Proactive issue detection and improved user experience:
- With observability, you can identify issues in real-time and quicken issue remediation.
- A fully observable network is crucial for ensuring services operate as expected and maintaining critical SLAs.
- Develop and implement comprehensive observability strategies for highly resilient applications, incorporating end-user application performance monitoring with the appropriate tools to guarantee customer satisfaction.
Dynamic adaptation in cloud-native environments:
- Due to the dynamic and distributed nature of cloud-native microservice environments, observability is the only way to achieve comprehensive visibility, enabling analysis of how, when, and where problems occur.
- Observability facilitates resource mapping within IT architectures, enabling interconnected functionality and streamlining automated application deployments.
- Use root cause analysis to pinpoint the location and cause of failures in a distributed application and implement the necessary fixes.
Adopting modern application architectures:
- Observability helps simplify application quality control during modernization and legacy transformation.
- Benchmark performance, analyze behavior, and manage application-level configurations.
- Achieve comprehensive visibility into application performance and availability, enabling efficient detection, troubleshooting, and root cause analysis of application issues.
Log-based threat detection:
- Utilize threat detection techniques to anticipate and address potential application performance interruptions, including pinpointing the root cause of errors.
- Use observability for continuous feedback via logs and reports, and leverage ML to predict potential issues.
Observability's true power lies in its ability to predict issues, understand the impact of changes, and provide solutions.
ManageEngine OpManager Plus comes with a pragmatic approach to observability, utilizing the power of AI and ML. By utilizing the data acquired from different network management tools, OpManager Plus offers a comprehensive observability solution. OpManager Plus delivers a comprehensive platform for system and application observability with built-in capabilities for network monitoring, bandwidth and configuration management, firewall analysis, and application performance tracking. Do you want to know how well this observability solution can work for you? Try OpManager Plus today! Leverage our 30-day free trial or book a personalized demo with our product experts to experience the power of OpManager Plus firsthand.
