Enterprise IT teams are continually challenged to manage larger and more complex systems with fewer resources. This requires a level of efficiency that can only come from complete visibility and intelligent control, based on the data coming out of IT systems. It is not surprising to see that a growing number of organizations are turning to IT Operations Analytics solutions to help them track performance, improve operational efficiency, and prevent service disruptions within their IT infrastructure.
IT operations analytics provide a robust set of tools that can generate the necessary insights to help IT operations teams proactively determine the risks, impacts, or outages that can occur due to various events that may take place in an environment. Gartner estimates that by 2017, approximately 15% of enterprises will actively use ITOA (IT Operations Analytics) technologies to provide insight into both business execution and IT operations, up from fewer than 5% today.
So how can we then use these analytics to effectively improve IT operational excellence? How can it help us make better decisions? And most importantly, how can it help prevent downtime and service disruptions?
Continuity Software recently conducted an infrastructure resiliency survey, with the goal of helping IT infrastructure and operations executives benchmark their organization’s performance and practices against their peers. The results presented here are based on responses from 230 IT professionals from a wide range of industries and geographies collected through an online survey.
Most survey respondents come from mid-size and large companies, with 40% of the survey respondents coming from organizations of over 10,000 employees. Over half of the respondents (54%) have more than 500 servers in their datacenter.
Some of the key findings of the survey include:
■ Avoiding productivity loss is the top driver for infrastructure resiliency initiatives, cited by 44% of the survey respondents. Additional drivers include ensuring customer satisfaction (22%), protecting company reputation (17%) and regulatory compliance (13%)
■ Service availability goals are becoming more ambitious. As many as 81% of the survey respondents have a service availability goal of less than 8 hours of unplanned downtime a year (compared to 73% in 2014), and 37% have a goal of less than one hour a year.
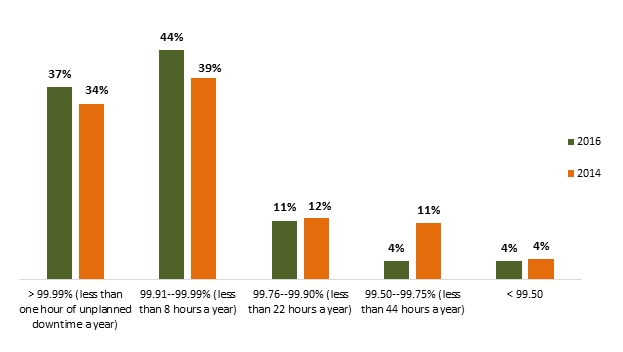
■ At the same time, as many as 39% of the respondents fell short of meeting their goal. 34% of the organizations surveyed had an unplanned outage in the past month, and 13% had one in the past week.
■ While cyber-attacks make headlines, they only cause a small fraction of system downtime. The most common causes are application error and system upgrades, each responsible for over four hours a year on average.
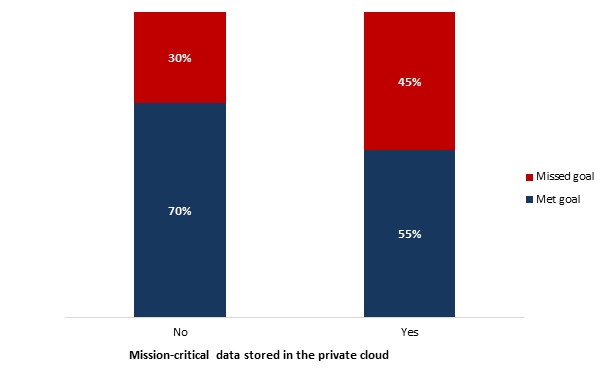
■ Although the majority of the survey respondents have moved some of their mission-critical systems to the cloud, those that have mission-critical systems in the cloud were less successful in meeting their service availability goals compared to organizations that have not made the move.
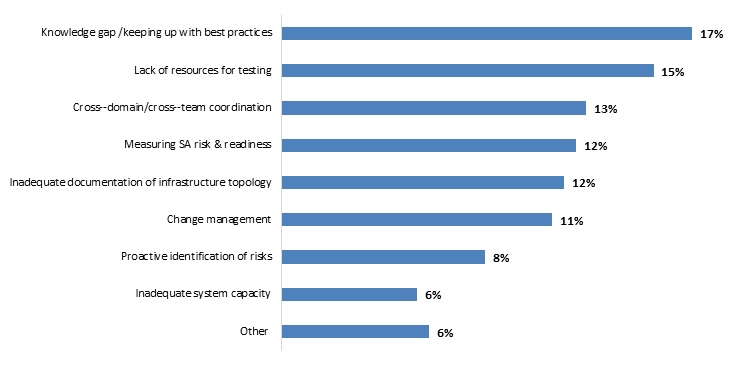
■ The top challenge in meeting infrastructure resiliency goals is the knowledge gap and inability to keep up with vendor recommendations and best practices. This challenge is significantly more prominent in the cloud environment and one of the primary factors why companies with a larger cloud footprint are struggling to meet their goals.
■ Large companies have a higher price tag on downtime. For 36% of the organizations with over 10,000 employees, the average hour of downtime costs over $100,000.
As IT environments become more complex and more systems are deployed in virtualized private cloud settings, having the right tools to manage IT operations becomes essential. IT Operations Analytics solutions that generate actionable insights across the entire IT landscape are helping IT teams be more proactive and efficient, allowing organizations to improve resiliency and prevent disruptions to critical business services.
Doron Pinhas is CTO of Continuity Software.