Some years ago, the computer systems' key focus was on performance and many articles, products and efforts were evident in this area. A few years later, the emphasis moved to high availability (HA) of hardware and software and all the other machinations they entail. Today the focus is on (cyber)security.
Read Dr. Terry Critchley's full paper on Resilience
These discrete environments' boundaries have now blurred under the heading of resilience. The main components of resilience are:
1. Normal high availability (HA) design, redundancy etc. plus normal recovery from non-critical outages. This applies to hardware and software. Human factors ("fat finger" syndrome and deliberate malice), are extremely common causes of failure.
2. Cybersecurity breaches of all kinds. No hard system failures here but leaving a compromised system online is dangerous. This area has spawned the phrase cybersecurity resilience.
3. Disaster Recovery (DR), a discipline not in evidence, for example, in May 2017 when Wannacry struck the UK NHS (National Health Service).
You can't choose which of the three bases you cover; it's all or nothing and in the "any-2-from-3" choice, disaster beckons. It would be like trying to build then sit on a two-legged stool.
In boxing, resilience in simple terms means the ability to recover from a punch (normal recovery) or knock down (disaster recovery). However, it has connotations beyond just that, inasmuch as the boxer must prepare himself via tough training, a fight plan and coaching to avoid the knockdown and, should it happen, he should be fit enough to recover and re-join the fray quickly enough to beat the 10 second count; financial penalties in our world.
When is an Outage Not an Outage?
This is a valid question to ask if you understand service level agreements (SLAs). SLAs specify what properties the service should offer aside from a "system availability clause." These requirements usually include response times, hours of service schedule (not the same as availability) at various points in the calendar, for example, high volume activity periods such as major holidays, product promotions, year-end processing and so on.
Many people think of a system outage as complete failure — a knockout using our earlier analogy. In reality, a system not performing as expected and defined in a Service Level Agreement (SLA) will often lead users to consider the system as ‘down' since it is not doing what it is supposed to do and impedes their work.
This leads to the concept of a logical outage(a forced standing count in boxing) where physically everything is in working order but the service provided is not acceptable for some reason. These reasons vary, depending at what stage the applications have reached but they are many.
Resilience Areas
Resilience in bare terms means the ability to recover from a knock down, to use the boxing analogy once more. However, it has connotations beyond just that inasmuch as the boxer must prepare himself by tough training and coaching to avoid the knockdown and, should it happen, he should be fit enough to recover, get to his feet and continue fighting. The information technology (IT) scenario this involves, among other things:
■ "Fitness" through rigorous system design, implementation and monitoring.
■ Normal backup and recovery after outages or data loss.
■ Cybersecurity tools and techniques.
■ Disaster Recovery (DR) when the primary system(s) is totally unable to function for whatever reason and workload must be located and accessed from facilities — system and accommodation (often forgotten) — elsewhere.
■ Spanning the resilience ecosphere are the monitoring, management and analysis methods to turn data into information to support the resilience aims of a company and improve it. If you can't measure it, you can't manage it.
Figure 1 is a simple representation of resilience and the main thing to remember is that it is not a pick and choose exercise; you have to do them all to close the loop between the three contributing areas of resilience planning and recovery activities.
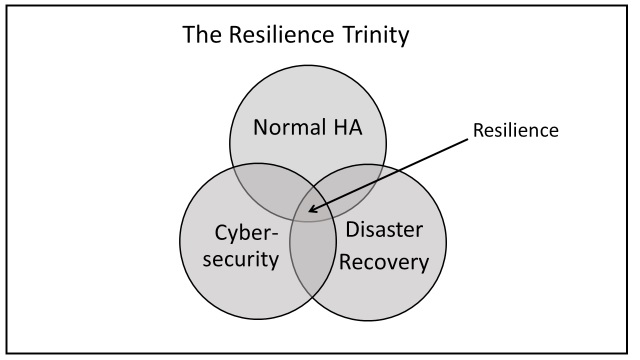
Figure 1: Resilience Components
Security(cybersecurity) is a new threat which the business world has to be aware of and take action on, not following the Mark Twain dictum: "Everybody is talking about the weather, nobody is doing anything about it."
The key factor is covering all the ‘resilience' bases at a level matching the business's needs. It is not a "chose any n from M" menu type of choice; it is all or nothing for optimum resilience.
To stretch a point a little, I think that resilience will be enhanced by recognizing the "trinity" aspect of the factors affecting resilience and should operate as such, even in virtual team mode across the individual teams involved. This needs some thought but a "war room" mentality might be appropriate.
The three areas considered in parallel (P) make for a more resilient system than different teams treating them in isolation as serial or siloed activities (S). Another downside of S is that it requires three sets of change management activities.
Conclusion
Like any major activity, the results of any resilience plan need review and corrective action taken. This requires an environment where parameters relating to resilience are measurable, recorded, reviewed and acted upon; it is not simply a monitoring activity since monitoring is passive, management is active and proactive.
Management = Monitoring + Analysis + Review + Action
This is a big subject which few understand in size or complexity but it has to be tackled.
Resilience is hard. If you think that throwing suitable, trendy products at the resilience design is the answer, you are deluding yourself. As Sir Winston Churchill said, in paraphrase; "All I can offer is blood, sweat and tears."