Is middleware resource monitoring the same thing as APM? No – but it is highly complementary with APM and organizations generally need both for complex, large-scale application environments that depend on middleware.
End to end resource monitoring is fundamentally different.
We see four general categories in the enterprise monitoring landscape:
1. Low level infrastructure monitoring, often open source or low-cost
2. Domain-specific admin and monitoring tools including database, server, log, and vendor-specific tools
3. Application-aware resource monitoring of infrastructure
4. APM, including transaction tracing and end-user monitoring
APM, and especially transaction monitoring, has its place. It is an important capability for some types of users such as developers who need to understand the behavior of their transactions and how they are performing. It is also very good at identifying code-based problems. If your problems are in the code, then APM can help. But what if the problem is not in the application itself but the infrastructure that supports that application? Most application performance issues are not code-based problems.
Oftentimes, the problems lie in the middleware tiers, servers and other resources. These are equally as important to monitor.
The Complexity of Middleware
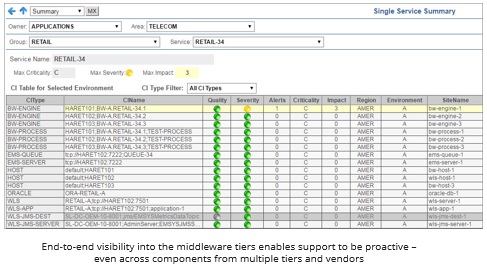
Middleware components are usually distributed, clustered and shared across multiple services and applications. Many organizations use middleware provided by multiple vendors across multiple tiers, on-premise, in the cloud, or hybrid. And a single middleware technology, such as TIBCO EMS, requires real-time and historical metric gathering for the EMS Servers, topics, queues, and destinations to really understand performance. An effective monitoring system will also provide information about other interdependencies. Is a problem with pending messages really occurring because of a CPU issue with a VMware host?
This all makes holistic monitoring tricky. So when an application problem lies in a middleware tier, your application support and middleware support teams require specialized tools to proactively identify the problem before the application is affected. If they are relying on end user or transaction monitoring for this type of problem, chances are the middleware components are going to be a black box. APM tools just don’t provide adequate visibility into the middleware.
So before you increase spending on APM tools, be sure you have the middleware tier covered and those support teams have the tools they need to be proactive in resolving the infrastructure level problems.
Ask yourself how you solve the majority of your Sev 1 incidents today. Are you using tools that help you understand the performance of your clustered middleware? Or are you using tools that help you understand your transactions and transaction throughput? The answer may help you in prioritizing your monitoring investments.
Ted Wilson is Chief Operating Officer at SL Corporation.