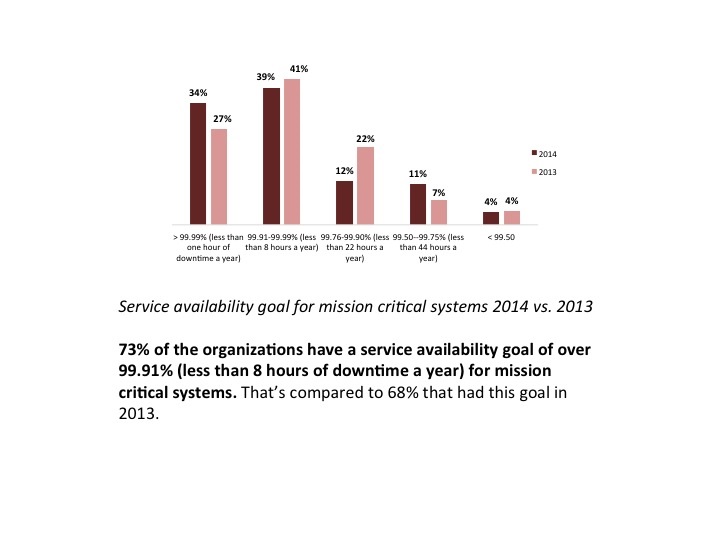
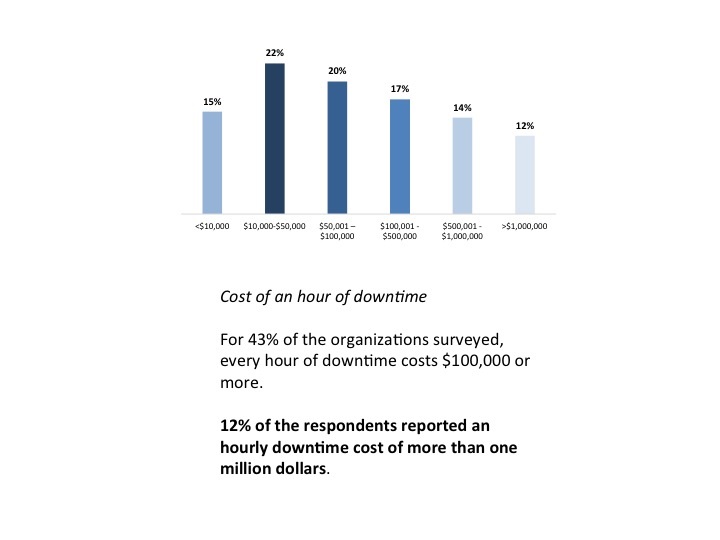
Almost three-fourths of organizations surveyed have a service availability goal of over 99.91% for mission critical systems, yet more than half of the companies had an outage in the past 3 months, according to Continuity Software's 3rd annual Service Availability Benchmark Survey.
The key findings of the report, based on responses from 155 IT professionals across a wide range of industries and geographies, reveal:
■ Over half of the companies (59%) had an outage in the past 3 months and 28% had an outage in the past month.
■ 41% of the organization surveyed missed their service availability goal for mission-critical systems in 2013.
■ 66% of the respondents have initiatives for improving service availability management in 2014.
■ Proactive identification of risks is the top challenge 20% of the respondents face in ensuring service availability.
■ The most common and most effective strategy for ensuring service availability is virtualization HA, used by 72% of the respondents this year compared to 63% in 2013.
It is discouraging to see that such a high percentage of organizations continue to miss their service availability goals, despite the tremendous effort and investment made across the infrastructure. IT teams are finding themselves in a never-ending chase to keep up with the pace of change across the IT landscape. As the survey results show, IT organizations are increasingly recognizing that a proactive approach to risk identification is more effective for outage prevention than playing catchup.
Doron Pinhas is CTO of Continuity Software.