With over 400K customers, Citrix is defining the digital workspace that securely delivers Windows, Linux, web, SaaS apps, and full virtual desktops to any device, anywhere. Citrix administrators at all these customers are the frontline for addressing dissatisfied end users of those applications and desktops. Unfortunately, even today, understanding real end-user experience in Citrix environments remains an unsolved puzzle.
AppEnsure conducted various surveys in the last six months and discovered some very consistent complaints that have been voiced over many years regarding end-user experience in Citrix environments.
With the rapid enhancements that Citrix is introducing in its frequent releases of XenApp/XenDesktop since 6.5 was introduced (recently 7.13 was made available), a new set of visibility and performance optimization challenges are being introduced. Left unaddressed, these limit the Citrix administrator's ability to understand, diagnose and improve the end-user experience of the delivery. From our surveys, it became evident, as the chart below illustrates, that Citrix administrators do not have the appropriate tools to readily identify performance issues affecting the end-user experience.
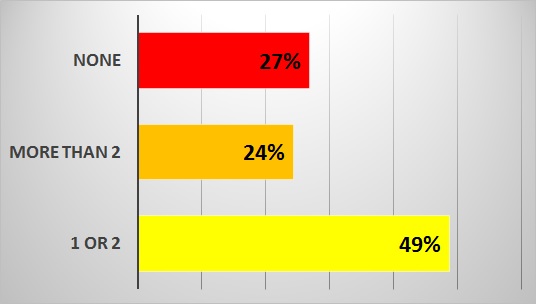
Even in circumstances where Citrix administrators are using multiple tools, there is the lack of visibility needed to solve performance issues with end-user experiences. Hence many administrators, not satisfied with the existing monitoring solutions that they have in place, are searching for new solutions with more effective technology to quickly resolve these issues.
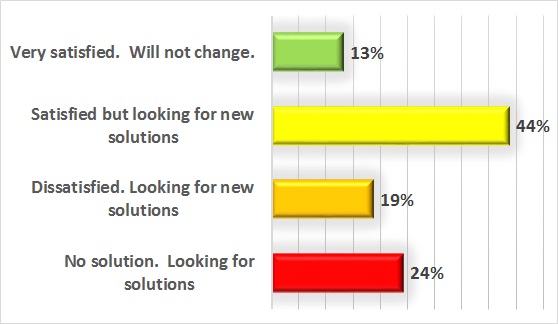
However, when applications and desktops are delivered over Citrix, the Citrix administrators in fact become the front-line for responding to all end-user complaints about slow performance, whatever the cause.
The common complaints that Citrix administrators receive from end-users have been very consistent over the years. Our survey confirmed the fact that most of the time Citrix administrators are fighting fires to address the common problems and just to prove that it is not “Citrix issue”, rather than trying to discover and resolve the actual root cause of the problem.
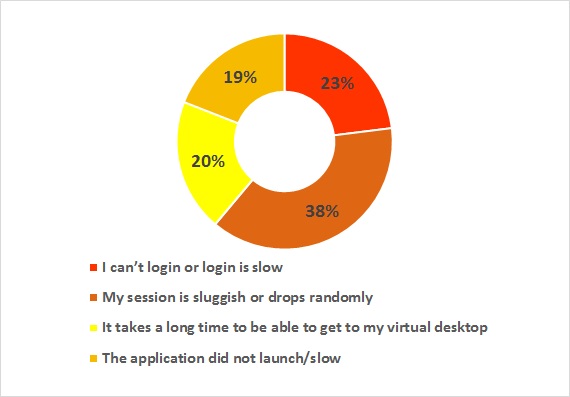
Typically, when end-user issues become show stoppers, Citrix administration resorts to a resolution path that typically involves “fire-fighting teams”, where experts from each technical silo bring reports from the specific tools they use to a collective meeting and compare notes to identify the actual problem. Often these meetings become “blame storming” meetings where symptoms are once again identified, but not the root cause. The frustration that Citrix administrators feel is reflected in the chart below.

Root Cause of the Continuing Enigma
An unsatisfying Citrix experience can stem from many factors external to the app itself. Issues with Citrix can often be traced to SQL, mass storage, Active Directory, and more. Citrix sessions are highly interactive and if there is a glitch, keystrokes don’t show up on time, the screen refreshes slowly, users may be disconnected and lose their work, and in general, productivity suffers. But more than 80% of the time, the root cause of the problem lies outside the Citrix environment.
Citrix is a delivery technology. Besides running on its own servers, Citrix interacts with the database servers, virtualization host servers, Storage Area Networks (SANs), web servers, license servers, applications, and network components such as switches and routers. End users call every problem a Citrix problem because every other component remains hidden behind Citrix.
As a result, a considerable amount of effort is required to correlate data across multiple expert groups to determine which of these components, including the Citrix servers themselves, actually is the problem. Since this takes time, most Citrix administrators are on the defensive trying to prove that it is not a Citrix problem, rather than trying to resolve the root cause of the problem.
What Should an Effective Citrix Monitoring Tool Provide?
The best and most effective way to improve the end user experience is to use a tool that measures the actual end-user experience on every device, not one that just infers response time through correlating commodity metrics (that never ends well).
Then, through repetitive measurement of these response times, it must automatically develop a baseline of response for any given day and time.
Finally, it must automatically alert IT Ops when performance is outside of the baselined norms expected. This gives IT Ops the proactive opportunity, over 80% of the time, to resolve issues before end-users see the slowness which triggers the complaint calls to the Support Desk.
In summary, an effective tool must provide:
■ Auto discovery of all end users and the applications and desktops they are accessing
■ Auto discovery and mapping of the complete stack and service topology without relying on (usually out-of-date) CMDBs
■ Auto baselining of response times for every user and transaction at any given time and date to give intelligent contextual alerting of end-user experience problems
■ Auto correlation of events across the stack, without having to pull out logs and manually review them all
■ Auto presentation of logon, App access, screen refresh times, etc. for all users and all transactions
■ Auto root cause analytics with clear directions on where the problem is and who is being affected
The list of key functionality enables Citrix administrators, who at last can resolve the puzzle, deliver fast end-user performance experiences and cancel the long-standing enigma.
Sri Chaganty is COO and CTO/Founder at AppEnsure.