The majority of site reliability engineers (SREs) will be working remotely post COVID-19, according to the 2020 SRE Survey Report from Catchpoint and the DevOps Institute.
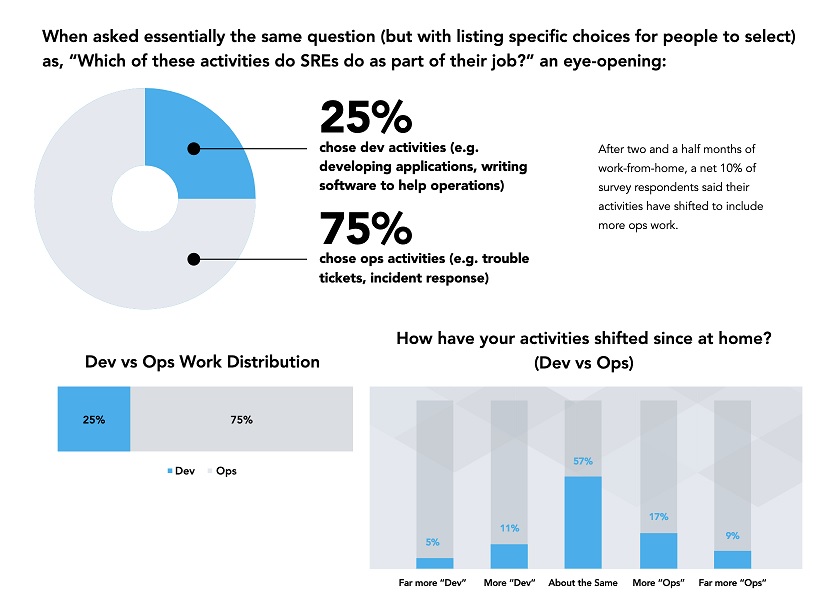
Google says SREs should be doing 50% ops work and 50% dev work, yet having a 50/50 workload split seems to be a pipe dream, according to the survey. The majority of respondents are currently spending 75% of their time on operations resulting in far less of their time being devoted to development.
Additionally, 53% of respondents said they were being involved too late in the application lifecycle.
When SREs are invited early into the development process, organizations can mature to more advanced observability resulting in improved service reliability, incident management effectiveness and customer satisfaction.
"Solving complex problems and ensuring reliability in today's highly distributed world can be very difficult and requires greater monitoring and true observability. Prior to the pandemic, most companies had a handle on end-user/customer experience monitoring for distributed systems," said Mehdi Daoudi, CEO of Catchpoint. "But now with a greater distribution of users comes new challenges and added reliability needs. True observability is the key to ensure reliability and customer experiences for all things distributed."
Jayne Groll, CEO, DevOps Institute, added: "SRE is one of the most innovative approaches to managing services since the early days of ITIL and is most closely aligned with the principles and practices of Agile and DevOps. The data in this report supports the rising criticality of both SRE as a practice and Site Reliability Engineer as a role for any organization trying to adapt to the digital age."
Highlights of survey results include:
Observability Components Exist - Observability Does Not
When asked what tool categories SREs are using today, the majority (93 percent) chose monitoring as compared with 53 percent choosing observability.
Additionally, when asked about their key responsibilities, the majority ignored those aligned with the observability pillars (events, metrics and tracing) highlighting the lack of true observability.
True observability requires monitoring of external outputs to determine how reliable internal systems function.
Heavy Ops Work Load Comes at a Cost
DevOps appears to be in a tug of war, and Ops is winning in the SRE community with the pre-COVID survey showing that 75% said they are spending the majority of their time on Ops, resulting in increased costs of owning and maintaining systems.
Perhaps widening the gap, the survey showed that two and a half months into working from home, the survey results showed a net 10% increase in Ops related responsibilities.
Challenges of the Shift to Remote Work
The post-pandemic environment has resulted in a major shift on where SREs will be located, with nearly 50% of SREs believing they will be working remotely post COVID-19, as compared to only 19% prior to the pandemic.
Additionally, 9% of respondents felt incident management has improved.
However, there are cautionary findings for organizations considering the structure of SRE teams post-COVID, as many respondents noted they are dealing with the following challenges:
■ 41% state that half or more of their work is a toil with mostly manual, repetitive, and tactical jobs that could be automated.
■ 52% said they spent too much time debugging
■ More than half of respondents felt that personal challenges included staying focused and having a good work/life balance while working from home
Recommendations for the SRE
Below are a few recommendations for SREs based on the survey's findings:
■ Be sure to include consideration for not only your code, but also the networks, third party services, and delivery chain components, to evaluate how well the three observability pillars are applied through this new digital experience observability lens.
■ Work to be included earlier in the development process should shift reliability further left to reduce cost, increase team alignment, and identify constraints that can be removed.
■ Turn newly surfaced, or previously-ignored challenges into strategic differentiators. Focusing on challenges like morale, employee experience, work/life balance, and employee engagement and sentiment may showcase a company's employee-first mentality to attract or retain top talent.