Microservices have become the go-to architectural standard in modern distributed systems. According to a recent report by Market Research Future, the industry shift towards adopting microservices is growing at 17 percent annually. Considering how microservices enable rapid application prototyping and faster deployments by reducing dependencies between individual components and services, this isn't all that surprising.
This independence of individual components is achieved by implementing proper interfaces via APIs to ensure that the system functions holistically. While there are plenty of tools and techniques to architect, manage, and automate the deployment of such distributed systems, issues during troubleshooting still happen at the individual service level, thereby prolonging the time taken to resolve an outage.
The Challenges
Troubleshooting is always taxing, but microservices make it even more cumbersome, as developers have to correlate logs, metrics, and other diagnostic information from multiple lines of services. The higher the number of services in the system, the more complex diagnosis is.
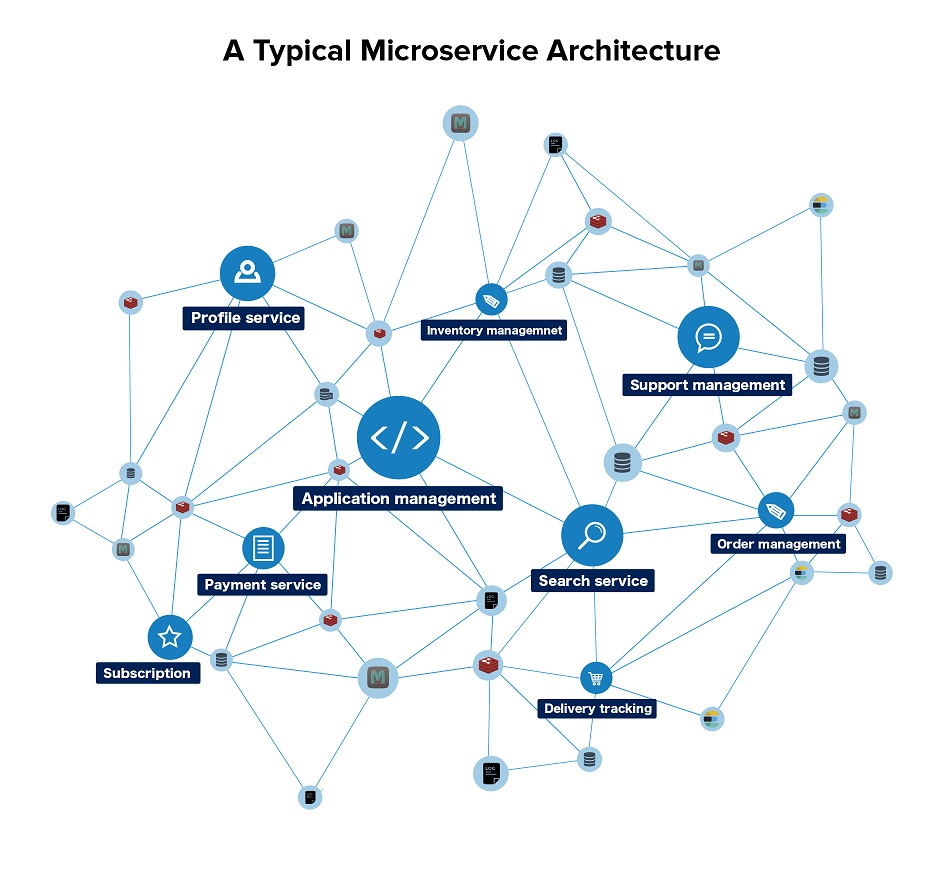
In the unfortunate event of an outage, the microservices environment poses two main challenges: the primary one is fixing the issue and bringing services back online, which, by itself, is a tedious and time-consuming process that involves correlating large amounts of service-level data and coordinating with various tools. But the far greater challenge is narrowing down the problematic service among the myriad of interconnected ones.
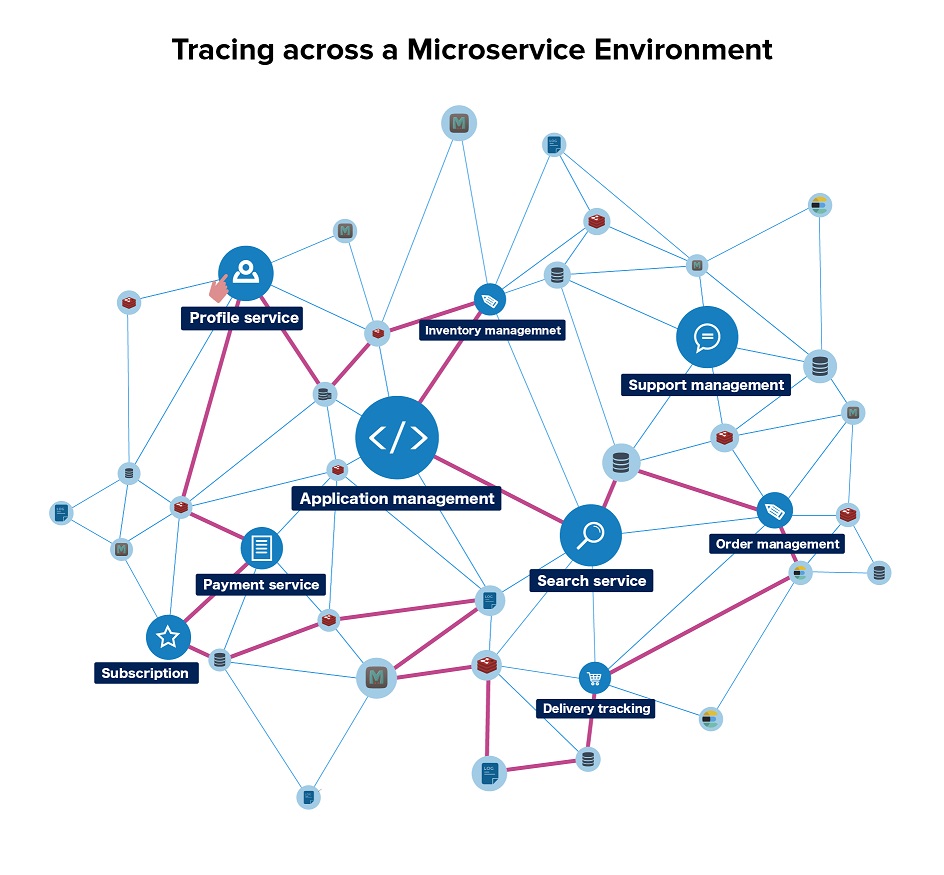
This is where distributed tracing comes into play. This mechanism enables DevOps teams to pinpoint the problem by skimming through the entire system for issues instead of tracing within the boundary of a service.
Causation and Not Just Correlation
Distributed tracing enables IT teams to visualize the flow of transactions across services written in multiple languages hosted across multiple data centers and application frameworks. This gives quick insight into anomalous behaviors and performance bottlenecks, and makes it easy even for a novice to understand the intricacies of the system.
In short, distributed tracing saves a lot of overhead in DevOps by presenting both a bird's-eye view of the system and the capability to zero in on the root cause of an issue.
The World Wide Web Consortium (W3C) is working on a standard that bridges the gap in providing a unified solution for distributed tracing. Very soon, distributed tracing will be an inevitable part in monitoring microservices.
The Road Ahead
Looking at the bigger picture, analyzing the massive sets of distributed traces would equip IT teams with more information than they usually get from mere troubleshooting. You can actually identify application behavior in various scenarios and derive actionable insights by studying these traces.
Soon, distributed tracing will not be considered as a mere problem solving tool; instead, it will take on an indispensable role in operational decision-making.
