Speedier network pipes that carry more information faster than ever before can be a windfall for enterprises looking to derive more business value from their underlying infrastructure. But there's a nefarious lining in there – when things speed up, they can get harder to manage.
Packets carrying crucial application information and content whizzing by in a blur can pose real visibility challenges IT pros haven't encountered before. Network and application performance management is undergoing sweeping changes thanks to not only faster networks but also migration to the cloud. And the implication for application and performance management are huge.
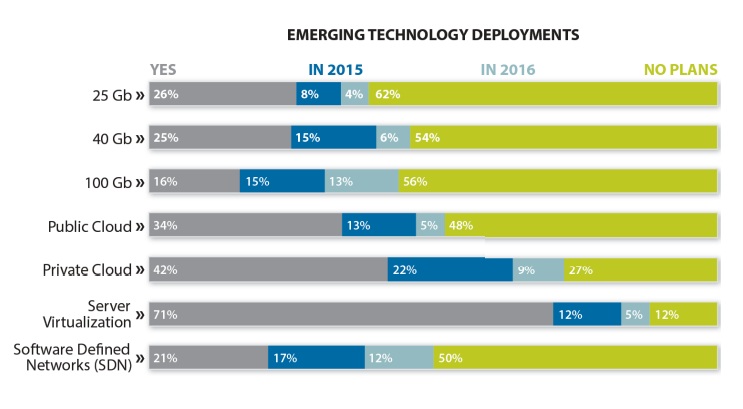
For the Network Instruments State of the Network Global Study 2015, we recently surveyed more than 300 CIOs, IT directors and network engineers, to get their take on how the migration to higher capacity and faster networks has affected their day-to-day duties monitoring application performance. What we found is that even though it seems like 10 Gb only just went mainstream, the insatiable demand for fatter pipes to push more content rich services is already outstripping its ability to deliver. Nearly 1 in 4 organizations already having deployed 25 or 40 Gb with upwards of 40% planning to do so in 2015.
More interesting was the fact that 60 percent had no plans to consider these speeds. We interpret this as a clear indicator that 25 and 40 Gb are likely at best short-term solutions to addressing the ever-increasing demands of more bandwidth with 100 Gb being the end-game (until at least 400 Gb arrives!). Results certainly suggest this, with 44 percent planning to deploy 100 Gb by 2016.
Network teams are in a bind: Do they get by with their existing 10 Gb infrastructure, maximizing their current investments while waiting for 100 Gb price points to become more cost effective? If not, are 25 or 40 Gb a viable option that will serve as a stop-gap solution? It's a difficult choice that each organization will need to consider carefully as they develop their network requirements for the next 5 to 10 years. It's amazing to think that 10 Gb, having only reached market dominance in the data center core in the past few years will likely be completely displaced in the largest, most demanding core environments in the next 2 to 3 years.
Of course, there are other technologies that are simultaneously maturing which must also be assessed in parallel. Ongoing cloud growth is now clearly a given, with nearly 75 percent expecting to deploy private and more than half public by 2016. This will certainly complicate the process of quantifying network bandwidth (along with latency) needs to ensure services continue to satisfy users' expectations wherever they may reside.
Likewise, the abstraction of all things related to IT infrastructure continues, with software-defined networking (SDN) rollouts expected to reach 50 percent by 2016. This too is an impressive number and speaks to the urgency of organizations as they drive to simplify network management, enable more scalability, improve agility, and reduce dependency on a single vendor.
Gigantic Implications for Performance Management
All these trends have gigantic implications for performance management. How will the tools needed to validate service delivery keep up with the deluge of packets? Since packets don't lie, having at least the option of analyzing and capturing all the traffic traversing the network means vendors' performance management solutions will need to continue offering their customers high-speed capture and long-term storage of this critical data.
From a cloud perspective, how will effective application visibility be maintained when hosting is done outside the confines of the traditional data center? Network teams are seeking ways of achieving this goal. Server virtualization - now nearly a given with nearly 90 percent of respondents stating plans to do so by 2016 - was yesterday's abstraction challenge. SDN will throw down a new gauntlet to maintaining monitoring visibility as the network is virtualized. Again, those responsible for network and infrastructure performance need assistance here.
So What Can Be Done? Below are several best practices for navigating this new landscape.
■ New ways of analyzing (including multivariate analytics and correlation), displaying, and reporting on infrastructure, network, and service health will need to be developed. Innovative instrumentation methods that can be deployed remotely and/or in ways that can be accomplished wherever services are currently deployed must be made available.
■ Maintaining visibility in SDN environments at the control and data planes will need to be addressed. Underlying infrastructure concerns don't go away with virtualization and in fact grow as increasing loads of placed on supporting hardware—monitoring solutions must provide this as well.
■ Automating this activity as much as possible will enable faster troubleshooting while concepts like RESTful APIs will enable tighter cross-platform solution integration and facilitate IT functional collaboration. These initiatives will ease the burden on network teams, shorten time-to-resolution, and ensure optimal service delivery. Just in time too, since the SOTN findings also show the same groups responsible for these duties must also spend increasing amounts of time addressing security threats. Almost 70% of network teams are already spending up to 10 hours per week, with another 26% greater than this amount.
These are exciting but challenging times for IT performance management. Emerging technologies offer great promise for enhanced future service delivery capabilities. Likewise, the threats are considerable; maintaining operational visibility so problems are quickly resolved, achieving optimal service performance, and increasing the ability to integrate across IT functional groups and solutions.