Is your website slow to load?
Page size and complexity are two of the main factors you need to consider.
Looking back at the trends over the last five years, the average site has ballooned from just over 700KB to 2,135KB. That’s over a 200% increase in five years!
The number of requests have grown as well, from around 70 to about 100.
Consider the data from WebPagetest.org (numbers overlap, due to the number of samples):
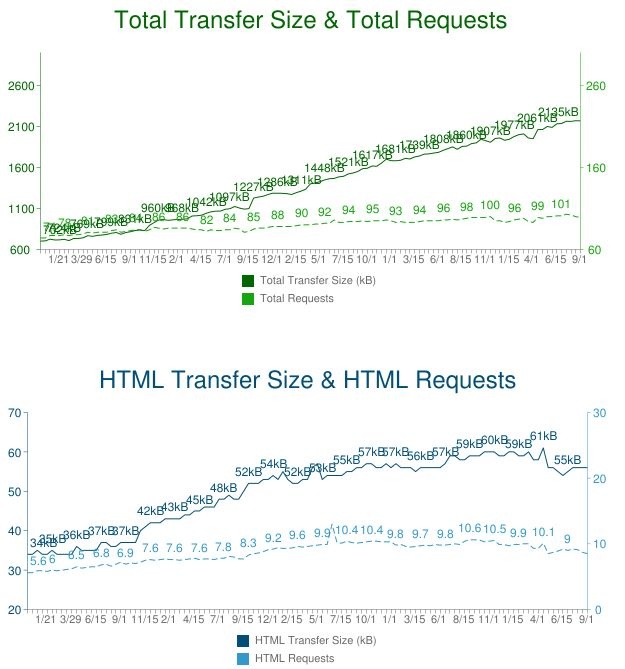
What’s going on?
Sites Are Opting For Complexity Over Speed
It’s clear from the data that sites are built with a preference for rich, complex pages, unfortunately relegating load times to a lower tier of importance. While broadband penetration continues to climb, the payload delivered to browsers is increasing as well.
This is a similar dynamic to what’s going on in smartphones with their battery life: the amount of a phone’s “on” time is staying static, even though processors have become smaller and more efficient. Why? Because the processors have to work harder on larger, more complex applications, and there’s pressure to deliver thin, svelte devices at the expense of the physical size of the batteries. Any gains in efficiency are offset by the work the processors have to do.
So yes, people generally have more bandwidth available to them, but all the data being thrown at their browsers has to be sorted and rendered, hence the slowdown in page speed.
Take images are a perfect example of this trend. The rise in ecommerce has brought with it all the visual appeal of a high-end catalogue combined with a commercial. The result: larger images – and more of them.
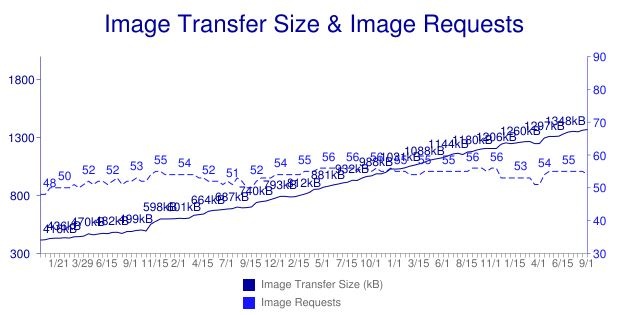
While the number of image requests hasn’t risen dramatically, the size of those images has. Looking at the above chart, the total size of a typical page’s images has grown from 418KB in 2010 to 1,348KB for today’s typical page, an increase of 222 percent.
You could go on and on about the impact of custom fonts, CSS transfer size and requests and the same for JavaScript, but the trends are the same. Other than the number of sites utilizing Flash decreasing due to the switch to HTML5, the story is always boils down to “bigger” and “more”, leading to a user experience that equates to more waiting.
What Can You Do About It?
Thankfully, there are steps you can take to get things moving. For example:
■ Consolidate JavaScript and CSS: Consolidating JavaScript code and CSS styles into common files that can be shared across multiple pages should be a common practice. This technique simplifies code maintenance and improves the efficiency of client-side caching. In JavaScript files, be sure that the same script isn’t downloaded multiple times for one page. Redundant script downloads are especially likely when large teams or multiple teams collaborate on page development.
■ Sprite Images: Spriting is a CSS technique for consolidating images. Sprites are simply multiple images combined into a rectilinear grid in one large image. The page fetches the large image all at once as a single CSS background image and then uses CSS background positioning to display the individual component images as needed on the page. This reduces multiple requests to only one, significantly improving performance.
■ Compress Images: Image compression is a performance technique that minimizes the size (in bytes) of a graphics file without degrading the quality of the image to an unacceptable level. Reducing an image’s file size has two benefits: reducing the amount of time required for images to be sent over the internet or downloaded, and increasing the number of images that can be stored in the browser cache, thereby improving page render time on repeat visits to the same page.
■ Defer Rendering “Below the Fold” Content: Ensure that the user sees the page quicker by delaying the loading and rendering of any content that is below the initially visible area, sometimes called “below the fold.” To eliminate the need to reflow content after the remainder of the page is loaded, replace images initially with placeholder ![]() tags that specify the correct height and width.
tags that specify the correct height and width.
■ Preload Page Resources in the Browser: Auto-preloading is a powerful performance technique in which all user paths through a website are observed and recorded. Based on this massive amount of aggregated data, the auto-preloading engine can predict where a user is likely to go based on the page they are currently on and the previous pages in their path. The engine loads the resources for those “next” pages in the user’s browser cache, enabling the page to render up to 70 percent faster. Note that this is a data-intensive, highly dynamic technique that can only be performed by an automated solution.
■ Implement an Automated Web Performance Optimization Solution: While many of the performance techniques outlined in this section can be performed manually by developers, hand-coding pages for performance is specialized, time-consuming work. It is a never-ending task, particularly on highly dynamic sites that contain hundreds of objects per page, as both browser requirements and page requirements continue to develop. Automated front-end performance optimization solutions apply a range of performance techniques that deliver faster pages consistently and reliably across the entire site.
The Bottom Line
While pages are still within the trend of seeing their size and complexity grow, the toolsets available to combat slow loading times have increased as well. HTTP/2 promises protocol optimization, and having a powerful content optimization solution in place will help you take care of the rest.
Still – if you can – keep it simple. That’s always a great rule to follow.
Kent Alstad is VP of Acceleration at Radware.