In Part 1 and Part 2 of this series, I introduced APM and Modern Observability, and dove into the history of the APM market. If you haven't read it, I recommend going back to the start of the series here.
The Birth and History of Modern Observability (so far)
Between 2012 to 2015 all of the hyperscalers (including Netflix, Google, AWS, LinkedIn, etc.) attempted to use the legacy APM solutions to improve their own visibility. To no avail. The problem was that none of the previous generations of APM solutions could match the scaling demand, nor could they provide interoperability due to their proprietary and exclusive agentry.
This also meant they were really unfit for keeping up with the sheer amount of innovation happening in the Cloud, due to the relatively small number of developers maintaining the agents and integration SDKs/interfaces.
To solve these shortcomings, Netflix, Google, and AWS all began working on their own projects to build telemetry pipelines, instrumentation layers, and control planes into their systems. You can see this today in numerous modern platforms, technologies, and stacks such as Kafka which was developed at LinkedIn, and Kubernetes a.k.a Borg, to orchestrate and scale workloads.
Two other Google projects, Open Census and Open Tracing, were aimed at developing the SDKs and protocols to replicate APM tracing capabilities in modern environments. There are numerous other examples. Ultimately, Google's projects succeeded in solving the scalability and interoperability limitations by developing open standards that could be implemented across any cloud. The community (and enterprises) saw the value immediately, and the projects became well-known but not widely implemented.
More recently, the CNCF merged Open Census and Open Tracing into OpenTelemetry, which is now an incubating project with massive adoption. OpenTelemetry provides a robust and highly customizable ecosystem of specifications, protocols, and libraries that results in a highly converged telemetry stream of data. What's more, it provides flexible and scalable pipelines that can be deployed at the edge via a standard set of SDKs, APIs, and protocols for discovering, instrumenting and enriching meta-data.
The best part lies in the fact it's all open-source, so if something you need is missing or broken, users are free to fork or contribute to the projects as needed.
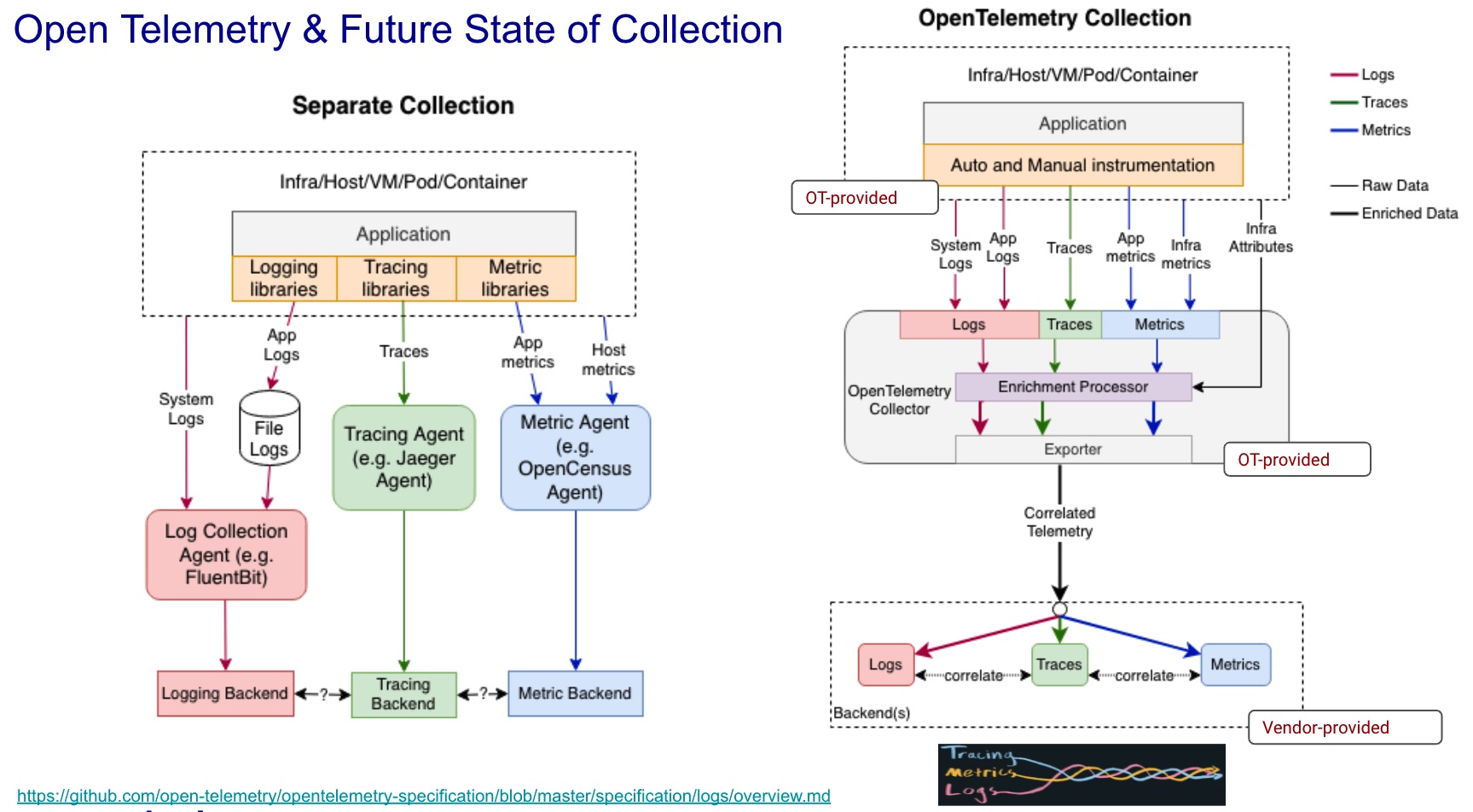
Click on image above for larger version
Modern Observability encompasses more than CNCF, open standards, protocols, and SDKs. Success with any new technology is highly dependent on the people engaging and the processes governing adoption and use. I define Modern Observability more broadly as a model or framework where all the things related to building observable systems are shifted left and declared as code.
Successful Modern Observability is led by the developer, and is defined early in the development lifecycle and continuously improved with each release. It becomes a declarative statement in the code-base deployed with the services and used as input to other GitOps models. Instrumentation is owned by developers. Developers declare in code what normal looks like providing the basis for a massive reduction in toil and churn. Observability as code enables automation in defining and deploying real-time Service Level Management (SLIs and SLOs), auto-remediation playbooks, and literally any AIOps use case.
Imagine if every service were able to reliably report the health of its internal state in real-time to the rest of the environment? How does that improve automation being orchestrated in a GitOps model and through toolchains? This is easily achievable with sound governance, frameworks, standards, and processes in place.
Giving developers the structure and tooling to declare everything as code actually matures software development teams to design not just observability telemetry but also security into the earliest phases of development, giving them a robust process to define "normal" operations "as code," along with the rules for defining Service Levels associated with the services being developed and deployed. This is really what these new ideas and methodologies such as Observability-driven development (ODD) are all about.
In the case of ODD, it provides a framework of governance and process by which developers standardize how they will build a service to be observable. It informs how they will standardize (based on each organizations' — or even each teams' — standards) the build and deploy pipelines, define what telemetry is emitted, and how they will define what normal looks like in the metrics emitted as a non-functional configuration in the codebase.
Because observability is not an afterthought in the development and deployment process, this simplifies the work developers already undertake to service the needs of business stakeholders such as customer success teams, business analysts, and the C-suite. It enables organizations to standardize how their teams digitally transform their applications, leading them to innovate faster and with observability built into everything to ensure reliability is properly measured and tracked over time.
Ultimately, for the mature developer, it creates an environment by which they are able to write services that are state-aware and can dynamically adjust to a variety of failure modes. For example, they may employ circuit-breakers to prevent already saturated downstream dependencies from compounding effects, or they may change to an alternate logic within the services in times of high latency, or dependency failure.
Closing Remarks
OpenTelemetry is increasingly the framework organizations are turning to solve their observability needs. It's now a CNCF Incubating Project and contribution and advancement in what it offers are accelerating rapidly. It provides a vendor-agnostic solution that is quickly becoming backward compatible even in monolithic on-premise environments.
Organizations adopting modern observability take ownership of the standards and practices for building observable systems. Doing so in a vendor-agnostic way means they forever own their telemetry and can continuously improve the state of observability just like they do the rest of their applications, services, and value streams. This is the bedrock upon which successful digital transformation happens. The freedom of knowing your telemetry is no longer tied to vendors ensures developers can take ownership and make technical decisions that drive successful outcomes for themselves, and the business.
As the standards and frameworks continue to mature, OpenTelemetry is poised to redefine how modern and traditional architectures are instrumented and observed. I for one firmly believe OpenTelemetry is going to be the gold standard for all telemetry acquisitions in the foreseeable future.
I truly hope you found this series informative. I also hope this gives you some ideas and strategies for improving your visibility, and innovation potential. Most of all, it's my hope that everyone can find a way to rely less on proprietary agents and more on their own resources and capabilities for building the next generation of applications and services.