The buzz around automation continues to grow, in every industry, sector and vertical — and for good reason. In IT Ops, the impact can be instant and huge, with improvement measured in the tens or even hundreds of percent as automation enables even a very lean team to operate at an outsized level. Automation can facilitate faster production, the creation of new products and the delivery of more services — and all in a stable, predictable, scalable way. And today, with AI and Machine Learning in the mix (aka AIOps), the possibilities and potential for automation are almost limitless.
So, how do you ensure your journey to automated IT Ops is streamlined and effective, and not just a buzzword?

Here are 4 golden rules to help you do just that:
1. Set good standards
2. Reduce complexity
3. Define and simplify processes
4. Automate wisely
1. Set good standards — powerful and specific
In general, standards can be thought of as specifications and procedures that have been designed to make sure the materials, products, methods, or services people use every day are reliable. Standardization is particularly relevant to IT automation, which is itself a computerized implementation of a standardized process. Put bluntly, computers are dumb and lack creativity. They do only what they're told, so we have to know exactly what we want them to do before they can do it. This is why only standardized processes can be automated successfully.
The key to optimizing automation is to create powerful standards that enable you to get the most out of your systems. These standards define how your systems communicate with each other, transfer information, look at and analyze data, etc.
A good example is the standardization of naming conventions, which, in the enterprise IT world, is always something of a challenge. If there is no standard in place regarding what one system is sending across, then the receiving system will just be guessing what to do with information it is getting. And, if it can't get the information it needs out of the data stream it receives, then a separate, manually-updated lookup table may be required, compromising the efficacy of the automation you wish to set up.

Consider, for example, the host naming standards illustrated in the image above. The more the naming standard is designed with your needs in mind, the easier it is for your systems to analyze the data, and pull out the critical information needed, such as the affected frame, geographical location, application served, etc. If used consistently across the organization, this standard becomes a solid bedrock for the assumptions that tools downstream can make about the data, and for the automation processes you put in place on top — for example, to issue automated alerts, response and remediation actions when a server has an issue.
2. Reduce complexity - keep only what you need
A useful rule of thumb is that you should be able to sketch out or explain what your IT environment does and how it functions in around a minute
Complexity is inherent in the dynamic modern-day IT environments in which businesses operate, but that doesn't mean that we should not try to reduce it wherever possible. A useful rule of thumb is that you should be able to sketch out or explain what your IT environment does and how it functions in around a minute. If you can't, automation may just exacerbate complexity. So, when you contemplate automation, you should see it as an opportunity to take a step back, recognize areas of unnecessary complexity and identify what can be done to reduce it. To do this properly, you need to make sure you talk to the people that are doing the work on the ground to find out about their actual experience.
In the diagram below, we see an example of how complexity can be dealt with by moving to a SaaS environment. Operating many systems on-premise that need to be managed and maintained comes at a huge cost — both financially and in terms of efficiency. By moving to a SaaS environment, rather than having to maintain hardware, the operating system, bug fixes and patches, network bandwidth, firewalls, load balancers and the on-prem application software itself, you just need to take care of one thing only: the configuration of your SaaS apps!
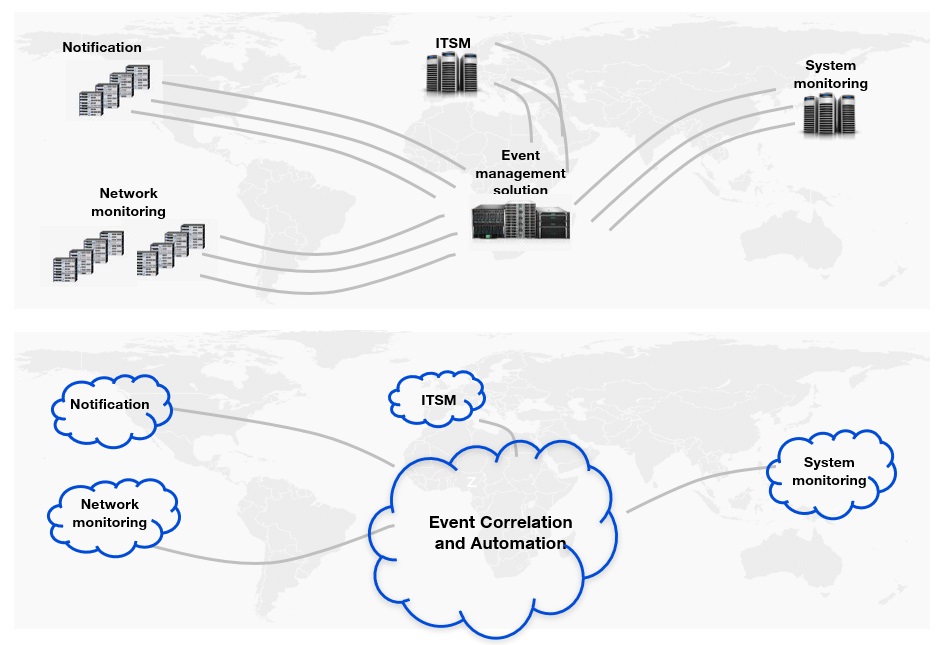
Tool rationalization is another good example. By reducing the number of tools you work with, you reduce the complexity of your operations.
Now, you can focus your automation efforts on taking care of simplified tasks, saving time and reducing overhead in the long term.