"You can fool some of the people all of the time, and all of the people some of the time, but you cannot fool all of the people all of the time."
Abraham Lincoln
Some of the outage figures quoted by organizations look ludicrously small to me. Without casting aspersions on the veracity of these figures (or availability statistics), I do feel that some examination of them is needed.
The non-availability of a system is often quoted thus:

where MTTR is the Mean Time To Repair a particular outage.
”We recognized we'd run the wrong job and restarted correctly in just 3 minutes, thus our MTTR = 3 minutes."
If you substitute the word "recover" for "repair" in the above definition you will be closer to the truth. However, your database(s) are almost certainly on Planet Zog as far as consistency is concerned and the "repair" of that will often take much longer. The correct definition of MTTR should be "mean time to recover" and the equation then looks as above but with a new MTTR:
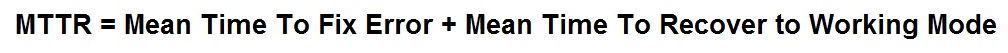
The last item in this equation I call the ramp up time, the time to get the show back on the road. This can be small but is often much larger than repair time, as shown in the diagram below. A decent Service Level Agreement (SLA) will opt for this definition of "fixed" for an issue and will include the ramp up time in the recovery time specification.
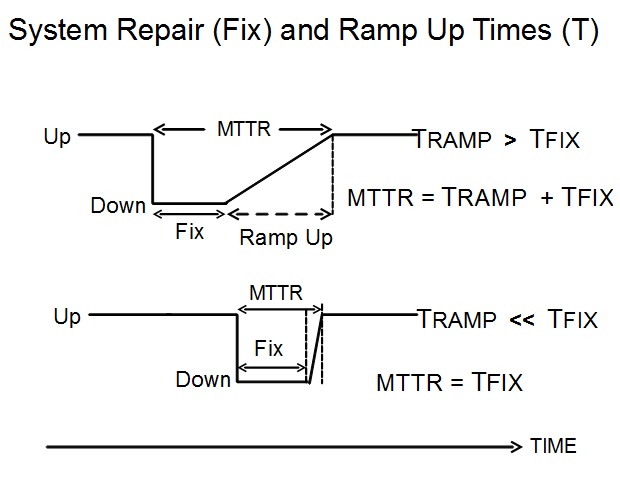
The recovery of a database or other data and metadata corrupted by human error or malware can take a considerable time to restore to the working status demanded by the end users.
This is borne out by several “Never Again” cases outlined in the Availability Digest (under the heading: Never Again) where financial bodies — banks, stock dealings — have repaired faults but taken many hours to recover normal working conditions again. ”The system was repaired at 11am and trading commenced normally at 2:30pm" is a typical (hypothetical) report on such situations.
The final point to make is that there are several viewpoints of an “outage” or period of "downtime", depending on your place in an organization. The end user's view will be that the outage lasts as long as he/she is prevented from using IT to do the job they are supposed to do. The server specialist's view might be that the outage of his hardware was a mere minute or two before it was fixed whereas the network person will say" “what's all the fuss about; everything on the network is working fine?”
It all depends on your viewpoint and I know what viewpoint the company CEO, the users and the board will take. Do you?
Dr. Terry Critchley is the Author of “High Availability IT Services” ISBN 9781482255904 (CRC Press).
