The average customer-facing incident takes nearly three hours to resolve (175 minutes) while the estimated cost of downtime is $4,537 per minute, meaning each incident can cost nearly $794,000, according to new research from PagerDuty.
As respondents' organizations saw an average of 25 high-priority/priority incidents in the last 12 months, the cumulative costs add up to just under $20 million per year, per organization.
Source: PagerDuty
"PagerDuty's global survey found that incidents have been driven by increased complexity, rapid expansion of digital services and insufficient investment in IT infrastructure maintenance," said Eric Johnson, CIO at PagerDuty. "The costs of these incidents are significant both financially and in lost consumer trust, which is why companies need to invest in automation to mitigate the risk and shorten the time an incident lasts. Investing in automation needs to be at the top of IT leaders' priority lists."
Other key findings of the data include:
■ Over half (59%) of IT leaders say that customer-impacting incidents have increased, growing by an average of 43% in the last 12 months.
■ 78% of IT leaders in travel say customer-impacting incidents have increased.
■ 68% of IT leaders in finance say customer-impacting incidents have increased.
■ Organizations with at least five manual processes in incident response incurred $30.4 million in annual costs of customer-facing outages vs. $16.8 million for those with at least five processes fully automated.
■ 69% of IT leaders say the board and management are failing to invest in protecting customer trust when outages occur.
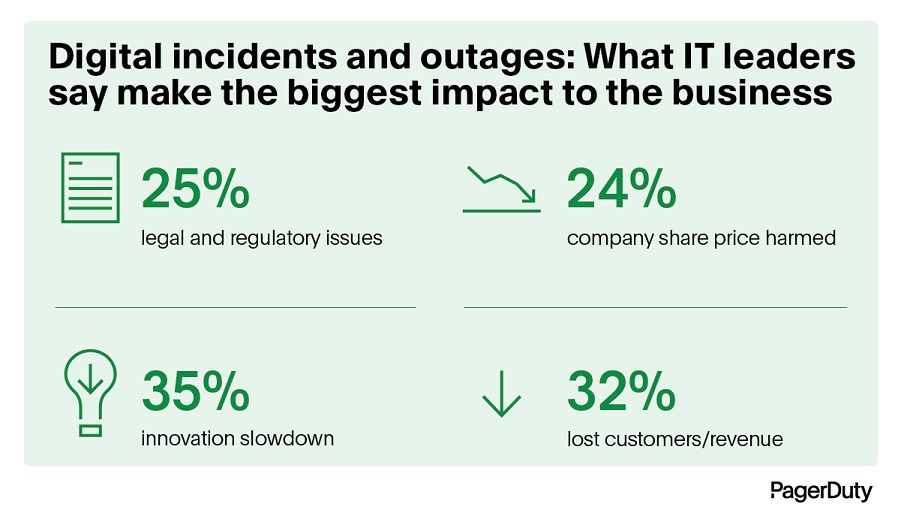
■ Nearly a quarter (24%) of IT leaders reported outages negatively impacting share prices.
■ More than ⅓ (35%) of IT leaders have seen higher levels of employee burnout.
■ More than 70% of IT leaders report that remediation, mobilizing responders, collaboration between teams and internal communications with stakeholders are yet to be fully automated.
Digital incidents continue to rise in number, last longer and cost more, but organizations are also understanding the critical role automation can play. 86% of IT leaders surveyed say that their organization is making strides towards fully automating the end-to-end incident response process.
"Digital incidents occur, and front-line responders are too often hindered in their ability to resolve incidents quickly due to fragmented IT environments, inadequate processes and inability to identify the right responders," said Jeffrey Hausman, Chief Product Development Officer at PagerDuty. "Automation can be a key enabler in achieving resilience in these increasingly complex environments."
Methodology: The survey — of 500 IT leaders and decision-makers of companies with more than 1,000 employees responsible for IT operations from the US, UK and Australia — was conducted online between May 31, 2024 and June 6, 2024 by Censuswide on behalf of PagerDuty.