Keeping networks operational is critical for businesses to run smoothly. The Ponemon Institute estimates that the average cost of an unplanned network outage is $8,850 per minute, a staggering number. In addition to cost, a network failure has a negative effect on application efficiency and user experience.
One area where networks tend to fail is in app delivery continuity. As multi-cloud environments grow more and more popular for hosting apps, finding the best way to route users across networks to their desired applications is becoming challenging. Not only are there a larger number of network exit points, but it is more difficult to define the best path to take for a user to access an app.
Typically the best path includes parameters like performance of the app itself or availability of the app, meaning that the app should be reachable via the path defined. Finding the best path can be a reasonably straightforward task, but only if all network components are functioning properly. As networks become more complex, a scenario where an application becomes unreachable (such as due to WAN failure) is all too likely.
The more complex the network, the higher the cost of failure. Enterprise Management Associates assessed the damage of one hour of WAN downtime in a 100-branch enterprise and a 1,000-branch enterprise; they found that a 100-branch enterprise loses $300,000 per hour of downtime, while a 1,000-branch enterprise could lose up to $1 million per hour.
Fortunately, a variety of solutions exist that could prevent such losses. One is a home-made multi-WAN vendor routing diversity; however, this is best for large enterprises with IP networking experts I&O.
A simpler solution is SD-WAN, or software-defined wide area network. SD-WAN automatically selects the route to take to reach an IP destination. But like any IP routing solution, it does not select the destination to go to; it tells you how to go, not where to go. It is a popular option for many companies, since it is excellent in efficiency and redundancy and can apply political or financial routing rules, not just technical IP routing.
However, a main drawback is that if any component on the path goes down, SD-WAN just drops the application traffic — it is unable to propose a new path to reach the same app hosted on a different server or in a different datacenter. Therefore, SD-WAN alone is not enough to ensure app delivery continuity; while it can control access to apps, SD-WAN is unable to guarantee that the app being requested is reachable by the user. For that, you need an application-aware routing solution to augment your network.
This is where DNS-based routing comes in. Before knowing how to go somewhere (with SD-WAN), you need to know where you want to go. DNS already performs the role of selecting the destination, and the best way to detect that the app is reachable is from the viewpoint of the user. Intelligent routing decisions should therefore be taken as close as possible to users, to enable "application aware routing"; a recursive DNS located near enterprise users is ideally placed.
Indeed, putting app routing control functionality into DNS located at the edge of the network makes sense. This is essentially how a DNS Global Server Load Balancer (GSLB), located at the network edge, would work; by continuously checking availability of app resources, following the same network path that will be used by the user to reach the app. The DNS GSLB could quickly detect an application access failure and "force" an alternative destination (a new IP address for the same application name).
Early failure detection, followed by automatic failover, would ensure that users are always routed to the app in an accessible datacenter. This would guarantee the desired app availability.
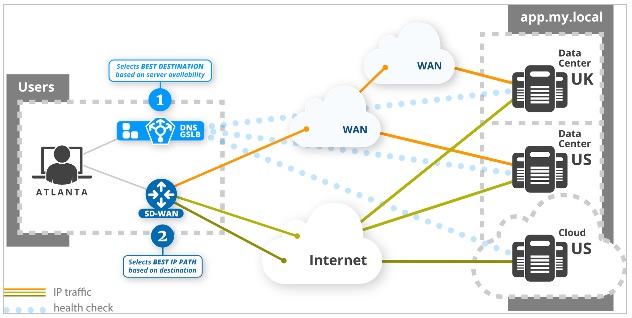
Adding DNS GSLB capability at the network edge covers scenarios that SD-WAN cannot handle. This includes detecting application access failure (IP path or server infrastructure or configuration), reacting on the user’s behalf on WAN failure, and selecting the best destination based on application response time metric. The bottom line is that everyone already uses DNS; it would therefore make sense to incorporate the GSLB functionality, and provide it at the edge.
DNS GSLB and SD-WAN are complementary to each other. SD-WAN chooses the how, DNS chooses the where, and adding DNS GSLB functionality as close as possible to users offers increased intelligence on the where. Moving DNS GSLB to the edge is disruptive in that it offers a smarter approach for controlling app traffic routing, one that is simple to implement and efficient in use.