This blog is an excerpt from DevOps, DBAs, and DBaaS by Mike Cuppet.
Start with Optimizing Application Performance with Change Management Improvements - Part 2
Performance Isolation
Several previous examples showed end-to-end, customer experience transactional times. Next, timings need to be gathered for each tier involved in the processing of the order history transaction. It is expected that the findings correlate with the end-to-end times: 5–17 seconds, minus outliers. Timings for workstation to web server, web server to app server, app server to database server, and the web service processing time provide clear transaction breakpoints. Look at the data in Table 6-1 .
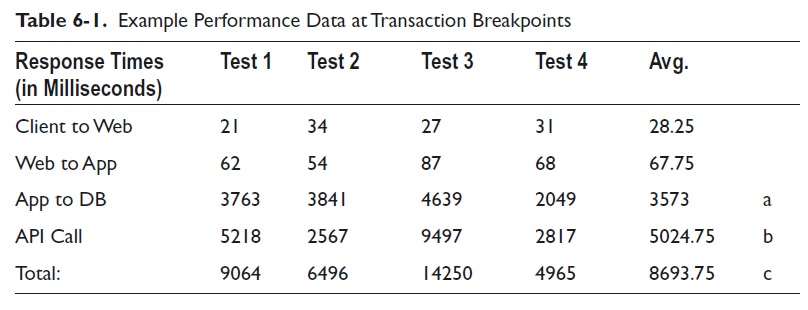
Immediately, two parts of the transaction register as extremely slow, with the average execution times shown by a and b. All four tests had total execution times within the 5–17 second range, with the average time shown at c. Ignoring the client-to-web-to-app segments and discovering the root cause for the slow execution times from the app server to the database server and for the API call should lead to significant decreases in response time.
DBAs can execute session traces to find which SQL statements are involved and how long each statement takes to return the result set. In this case, the excessive time is being spent in the database, caused by the query having to do a full table scan of the order table to get the order numbers to be pulled from the order history collection. A trigger is also in place that writes an audit record to a table that shows high insert contention.
The DevOps team agrees that an index is needed for the order table and that the audit table contention, although not good, is not critical enough to address right now because the contention accounts for only a few milliseconds. The contention issue is not a priority in the backlog. The index add is a priority fix to be implemented immediately after testing, bypassing the standard backlog process.
A DBA writes the Create Index statement and checks the code into the repository for the CI server to incorporate into the main code branch and to test. In parallel, a developer punches out a new test that would specifically execute the query with the new index, reporting the execution time in an e-mail to the entire DevOps team. The e-mailed results show an average execution time of less than 100 milliseconds; the team then releases the code for deployment.
After the deployment, the product manager reaches out to a subset of the users who reported the problem, with feedback similar to "It seems faster, but it is still too slow." Understanding that less than 50% of the transaction time has been addressed so far, the team begins to investigate the API call slowness. The cloud provider's hourly transaction time report consistently shows response times under 300 milliseconds, leaving the network in question. Initial checks show excellent round-trip response times.
Leaving only the WAN segment as the possible culprit, the DevOps team requests that the network team monitor the WAN. After several days, the network team reports that three times daily, at different times, a large volume of data was sent from the Oracle database server to the cloud provider, resulting in substantial packet losses, retransmissions, and connection timeouts. The teams quickly conclude that the job responsible for uploading order history data could be causing the problem. Comparing the network saturation times with user reported slowness times confirms a correlation within the business day. Network saturations during the night did not conflict with user transactions.
Further investigation found that the upload jobs were not running at the same time daily, as planned a year prior during the implementation. Instead of the job starting at a specific time during the night, the job start time was being set to when the job completed, causing the start time to drift until eventually running during the business day.
Separately, what was supposed to be a single daily upload turned into three daily uploads. The upload job was inadvertently scheduled three times, and each job loaded the same data set for the day because record selection included all records older than 180 days. To complicate things further, the same job was failing to remove the order history records, causing the upload record count to increase daily. Further investigation revealed that the MongoDB database had significant numbers of duplicate records.
The DevOps team developed a plan to first empty the MongoDB database, followed by uploading all the order history records in scope, purging the same records from the Oracle database, fixing the job code to make sure that records are deleted daily, and finally removing two of three scheduled jobs. The much smaller data set being uploaded during the night resulted in the user reporting excellent application performance, better than ever. It turns out that the upload issue pushed users past what they were willing to consider acceptable application performance: less than 5 seconds. Additional response time improvement came from the Oracle query fix that was responsible for the preupload problem average times of nearly 5 seconds. With both issues resolved, response times were subsecond.
The two changes that made application usage very acceptable for the users could be reported as successful or a failure, except now you know that the change management report needs to include details about how the change made an impact on the users and the business. Not recording the benefits in the change record seems irresponsible in light of DevOps practices.
Maturing change management from infancy with the limited vocabulary of success or fail evolves change management into a business-empowering function. DevOps speeds change delivery, but only after excessive testing that is purposed to not allow defects to proceed. It is important to note that change management must shift-left several steps from being a production release process to become a milestone starting at code check-in through deployments; change management is not a production-only tool. Changes identified as successful by developers testing on their workstations must include performance considerations, which must be rectified as needed before being introduced into the full product code base. Additionally, CI testing must include load and stress testing to ensure that the code performs just as quickly when competing with peak load times during the business day.
Manually troubleshooting a performance problem is time-consuming, as demonstrated here. Investments in APM or similar tools with different acronyms set the business up with the capability to proactively monitor applications, allowing performance corrections to be implemented before users are impacted. Reacting to real-time performance trends sure beats reacting to user complaints.
Change management seems an unlikely candidate for application performance improvement. DevOps again dispels the status quo by morphing a dreaded paperwork exercise into an effective communications tool. Reporting business improvements to customer experience or company financials, the DevOps team becomes a business partner known for speed to market, agility, and the willingness to accept business changes as routine, not scope-expanding challenges. Establishing DevOps principles as the cultural norm shifts the business' perception of IT, which is a much-needed good thing.
