SLOs have long been a staple for DevOps teams to monitor the health of their applications and infrastructure. They're incredibly useful in informing decisions to prioritize feature vs. reliability work, in addition to ensuring organizations can deliver on the service levels promised to their customers.
Now, as digital trends have shifted, more and more teams are looking to adapt this model for the mobile environment.
This, however, is not without its challenges.

Teams struggle to apply the SLO model to mobile for reasons that are both organizational and technical.
From an organizational perspective, there is often a gap between DevOps and mobile development teams. They have very different levels of expertise when it comes to observability (usually the domain of DevOps), are working with different tools and languages, and often rely on completely siloed datasets to understand mobile app performance.
Bridging this gap is the first and foremost step toward developing an effective SLO practice for mobile. To be successful, you need the expertise of both DevOps/SRE and mobile engineers. In practice, this means closer collaboration between these teams, particularly with shared observability tooling and data. Tools that offer features such as distributed tracing, for example, are very useful in this regard, as they help engineers directly connect what's happening on the the frontend with what's happening on the backend.
Building effective mobile SLOs requires the shared expertise of DevOps/SRE/Observability teams and mobile engineers
From a technical perspective, there are a number of factors that make mobile wildly different from the backend environment, and all of these affect how you build and monitor effective SLOs. Let's consider the most critical of these factors and how to address them.
Measuring Services Alone Gives You a Very Incomplete Mobile Picture
While backend SLOs are often focused on the availability or latency of a single service, using this approach is not helpful for mobile. That's because it only gives you a single piece of the picture, ignoring all of the other technical elements that are involved in ensuring your end users can actually achieve what they want to on your app.
You may be monitoring a backend service, for example, which is functioning very well. However, your end mobile users may still be complaining about a slow or stalled feature that relies on that service. If the issue is rooted in client-side processing problems, a standard backend SLO will fail to capture it. For this reason, mobile SLOs should be built around end-to-end user flows which may contain many technical components, both on the client side and server side. Examples of these include a checkout flow, an "add to cart" flow, or a login flow.
Mobile Is a Dynamic Runtime Environment with Many Variables
In the backend environment, you're likely working with a very limited number of physical or virtual machines with well-known specs and variables that are largely in your control. You know which software versions you're running, and you have the ability to manage things like storage and processing power.
All of these assumptions go out the window when working with mobile. Your app may be running on thousands of different devices around the world across multiple Android and iOS versions. There's also likely many versions of the app itself out there, as you have almost no control over if/when end users run a software update. Add into this mix unreliable network access, competition for device resources with other apps, background/foreground switching, and unpredictable user behaviors and the permutations are nearly infinite.
How do you account for this variability to build effective SLOs?
A lot can be mitigated by identifying your more critical population groups and isolating the data powering your SLO to these users and devices.
For example, you may choose to focus only on the most recent version of your app, and filter out telemetry coming from older versions. Or, you may prioritize users running on higher-end devices since your app requires a high-level of processing power to run optimally. In other cases, you may choose to focus on certain geographic markets as that's where the majority of your app revenue comes from. When you've determined both your business and engineering priorities, you can refine your mobile SLOs to reflect them.
Data Powering Your Mobile SLOs Will Inevitably Be Delayed
Monitoring backend infrastructure typically means having access to real-time data. Unfortunately, this does not hold true for mobile. Receiving data from devices out in the wild can take anywhere from a few seconds to a week or more, depending on when users close and reopen your app. This often means operating with delayed or incomplete data, or data that's out of order — all of which can seriously affect your SLOs and how you interpret them.
There are a couple of things you can do to account for data delays. First off, you'll want to ensure your data is timestamped to when the event occurred for the user, not when it was received by your servers.
Second, you'll have to consider your aggregation and analysis windows. You might choose to use longer aggregation windows to collect as much of your delayed data as possible, or opt for smaller windows with some "delay" built in to offset the impact of when your data is flowing in.
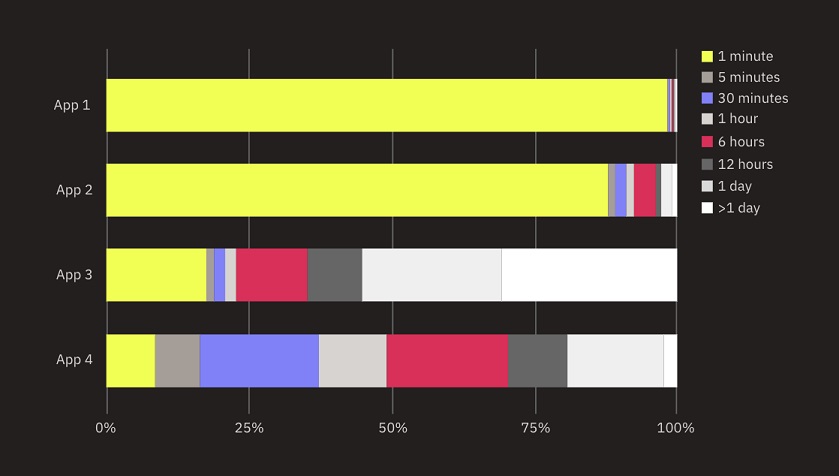
For some mobile apps, the backend receives the majority of data within a few minutes, but for others, up to 30% of data is delayed by a day or more, as shown in this chart of anonymized data from Embrace. The distribution of delayed data coming in for a number of anonymized apps (source: Embrace)
Key Takeaways
Adopting an SLO model is a great way to modernize how you approach mobile observability. It does, however, come with some organizational and technical challenges. Fostering a culture of true collaboration — across tools, data, and workflow — between mobile and DevOps/SRE teams is the first step. From there, engineers can combine their individual expertise to address the monitoring challenges that are unique to the unpredictable, often chaotic mobile environment.
This will inevitably be an iterative process, as you learn more about what data you're able to realistically collect and what performance thresholds are tolerable for your end users.
